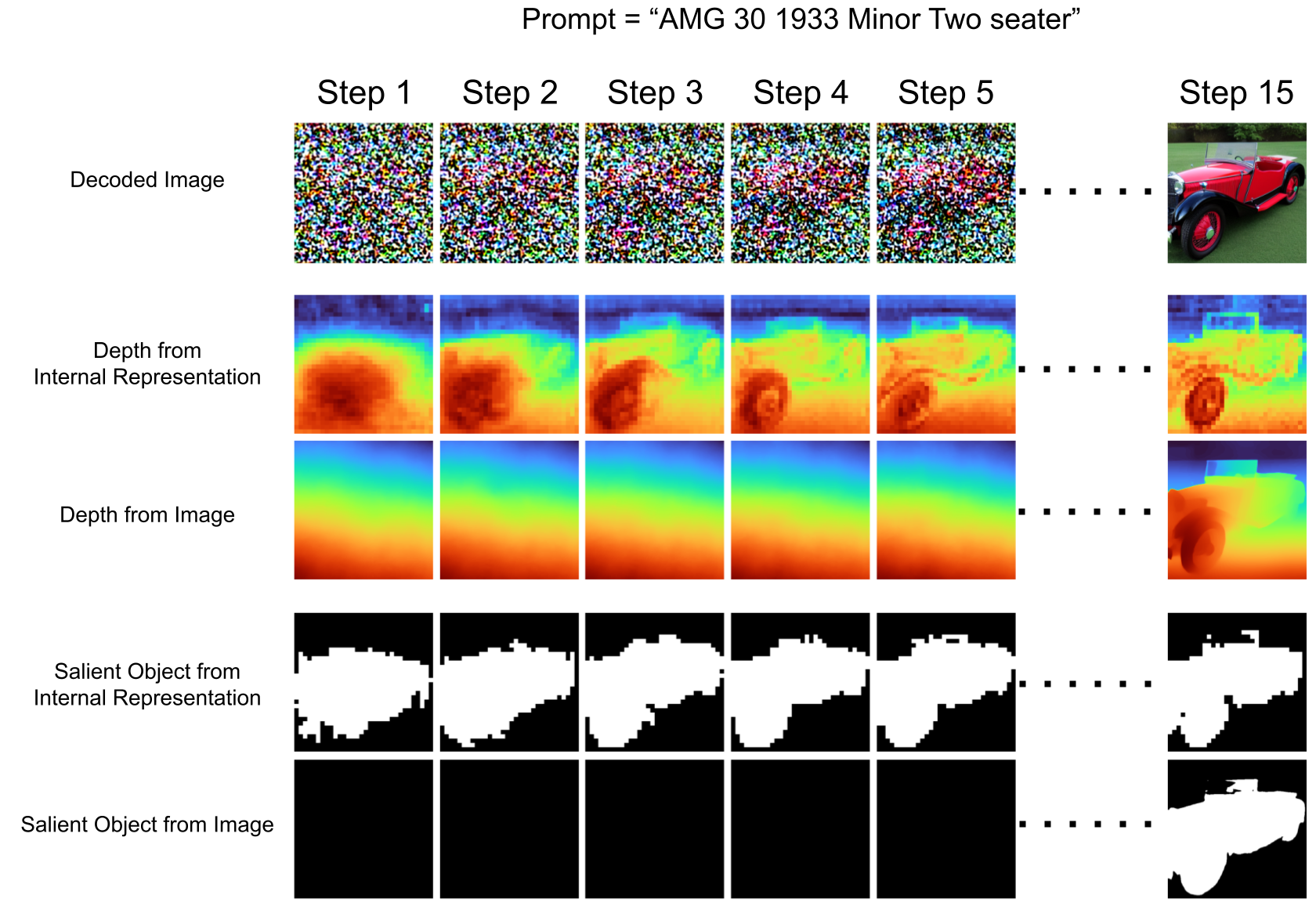
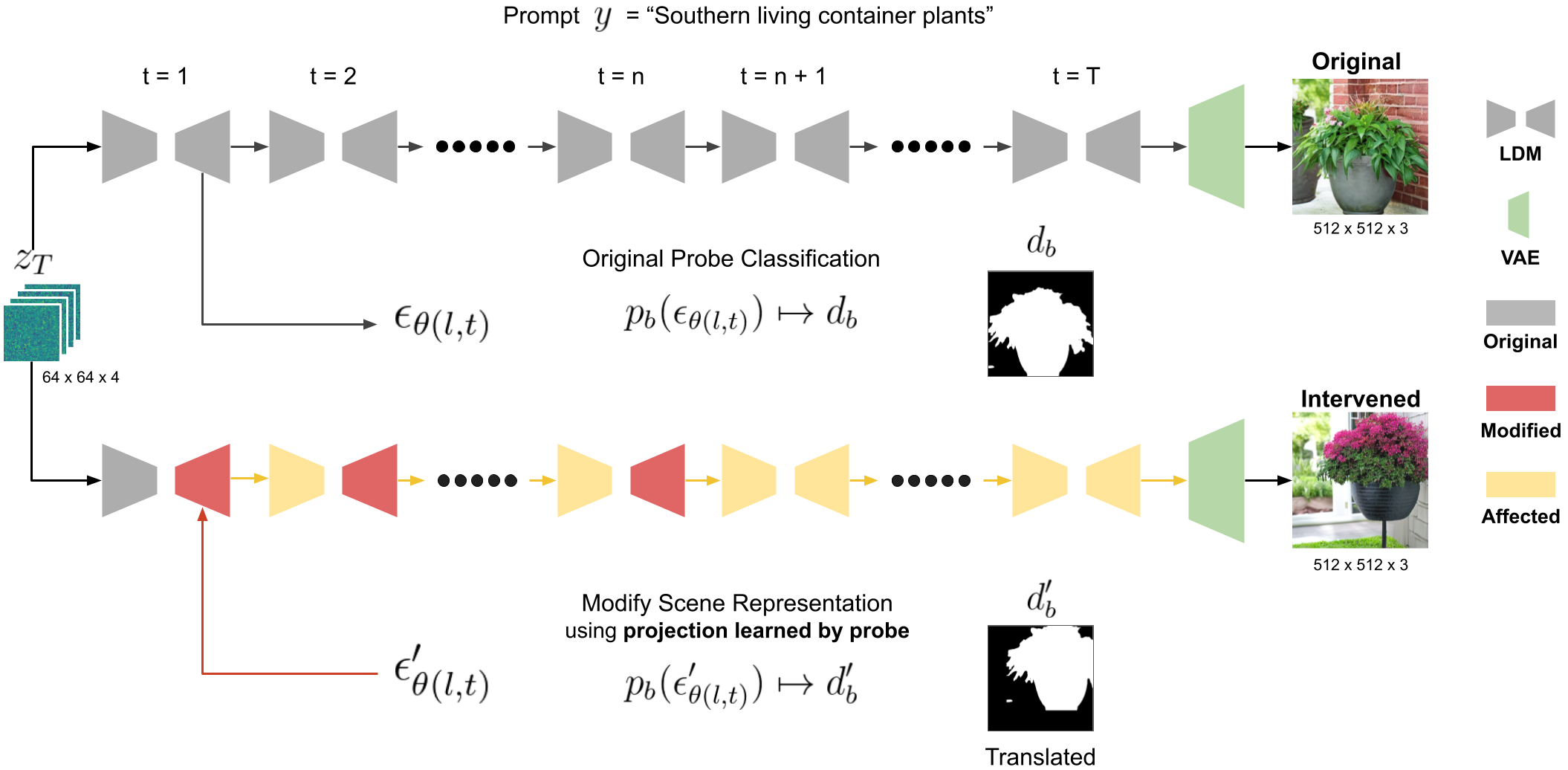
We implemented this intervention as a new text-to-image generation method.
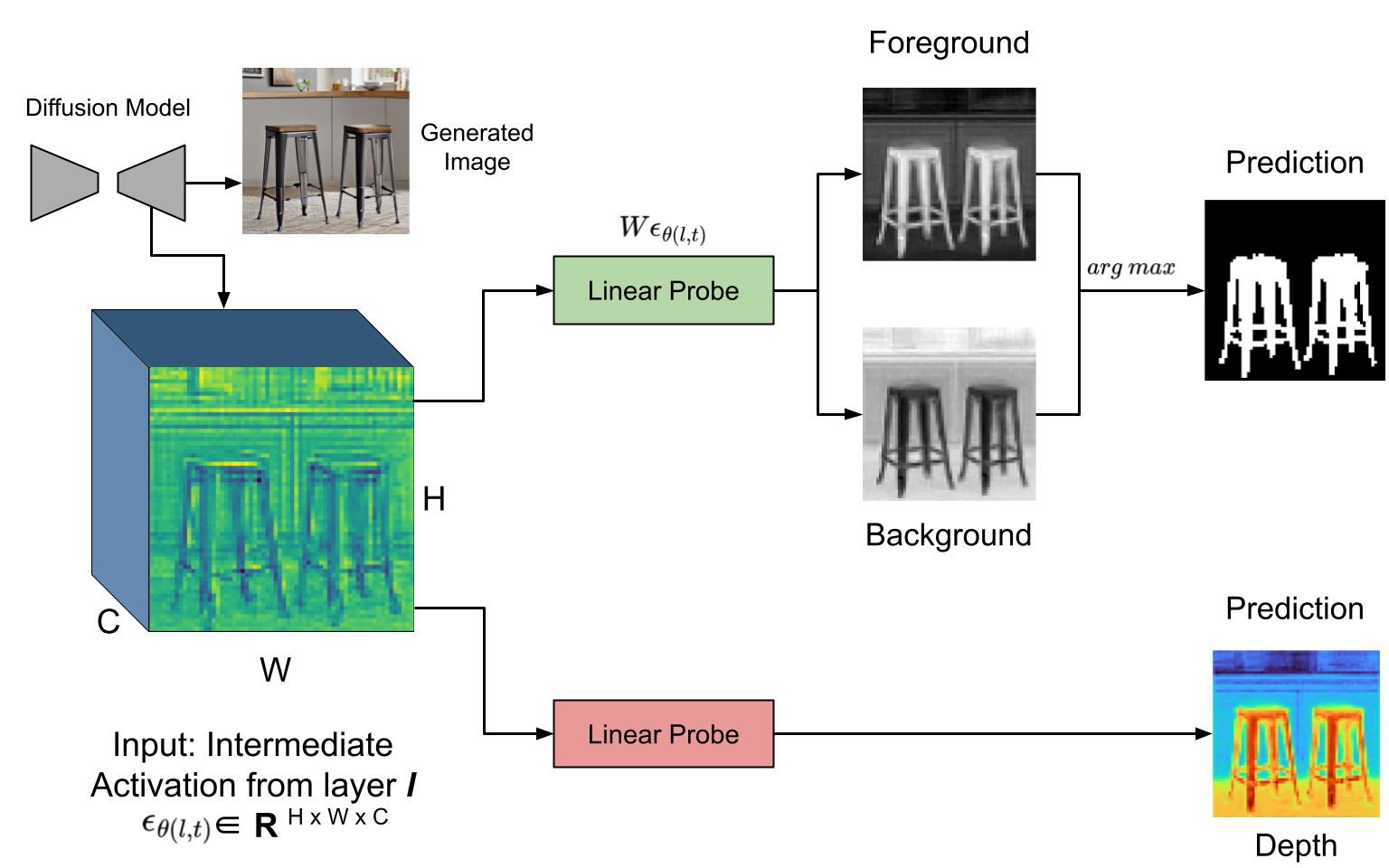
In the original image generation pipeline (upper part of the figure above), we train linear probes on the model's intermediate activations to predict the foreground of a generated image.
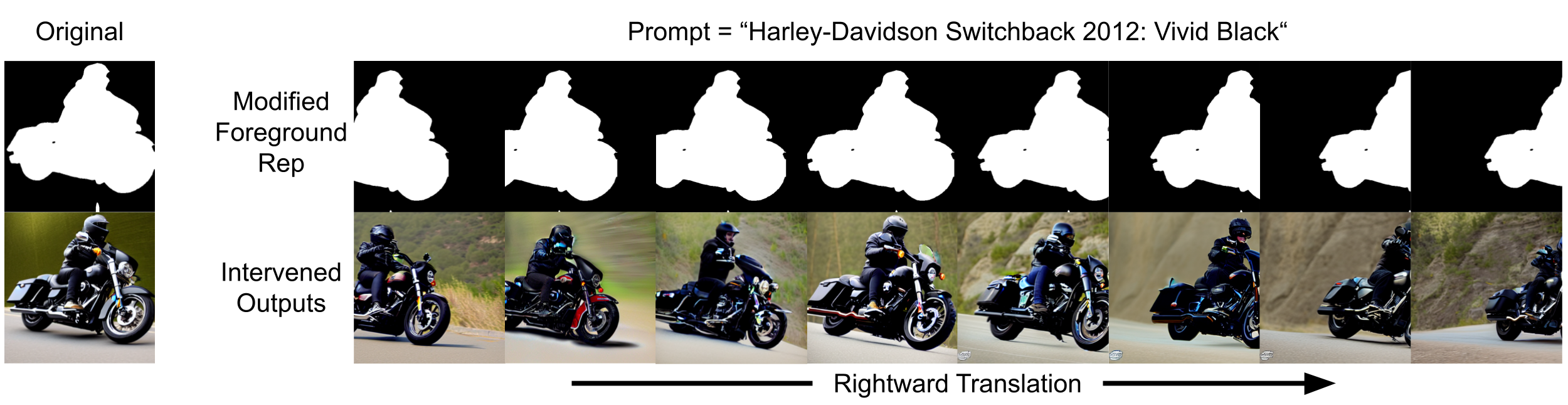
In the intervened image generation pipeline (lower part of the figure), we modify the intermediate activations using the projection learned by probe so a pixel's foreground and background property changes to match a new foreground map d'b. We made no changes on the model's weights, initial latent vectors, random seed, and prompt.
Ideally, if a causal link between the internal representation and scene geometry exists, changing the internal representation of that scene property should affect that property in the generated image accordingly.
|