

Motivation
Why identify reasoning differences among LRMs?
Recent works show that the performance difference between LRMs are connected to their reasoning habits [1] and the structure of their thought processes [2]. Nonetheless, these works analyze the reasoning patterns of individual LRMs using a taxonomy of reasoning behaviors defined by researchers prior to the analysis. This deductive approach may overlook the subtle differences in reasoning patterns that are not captured by the researchers' intuition.
We propose LLM-proposed Open Taxonomy (LOT), an automatic prompt engineer (APE) algorithm that simulates the workflow of inductive coding in qualitative research to create a taxonomy of reasoning patterns that set different LRMs apart. Compared to existing APE methods, LOT is designed for long-text classification, as it decouples the generation of classification prompts into separate forward passes. This enables LOT to capture the sysmatic differences (global) among long texts with observations of limited examples (local) in a single forward pass.
Summary of our contributions
Applied LOT to identify reasoning differences among 12 LRMs over 5 datasets
CASE STUDY: Reasoning features identified by LOT has causal impact on Qwen3 models' performance
How LOT works
Inductively construct a taxonomy of LLM's distinct reasoning habits
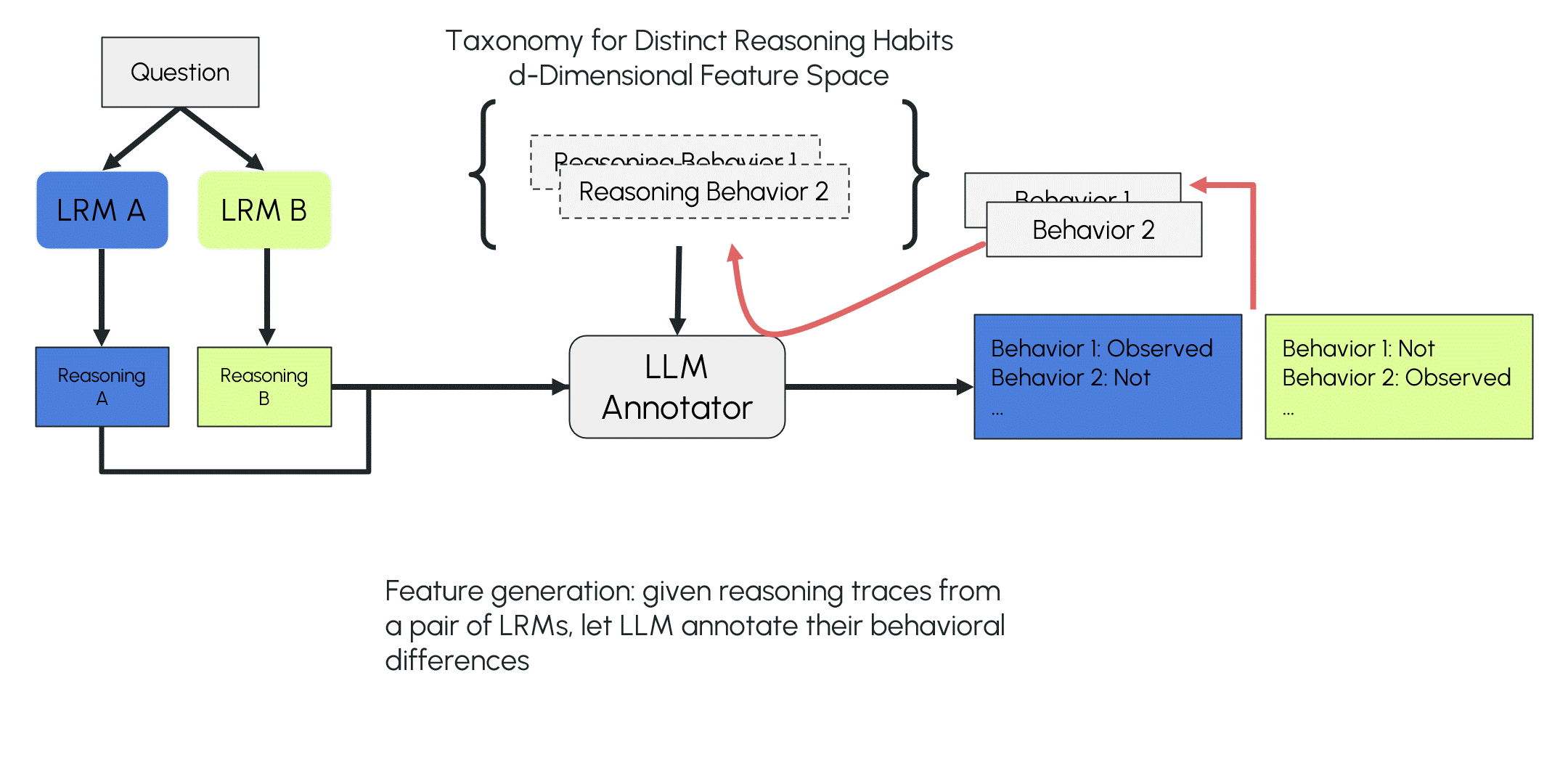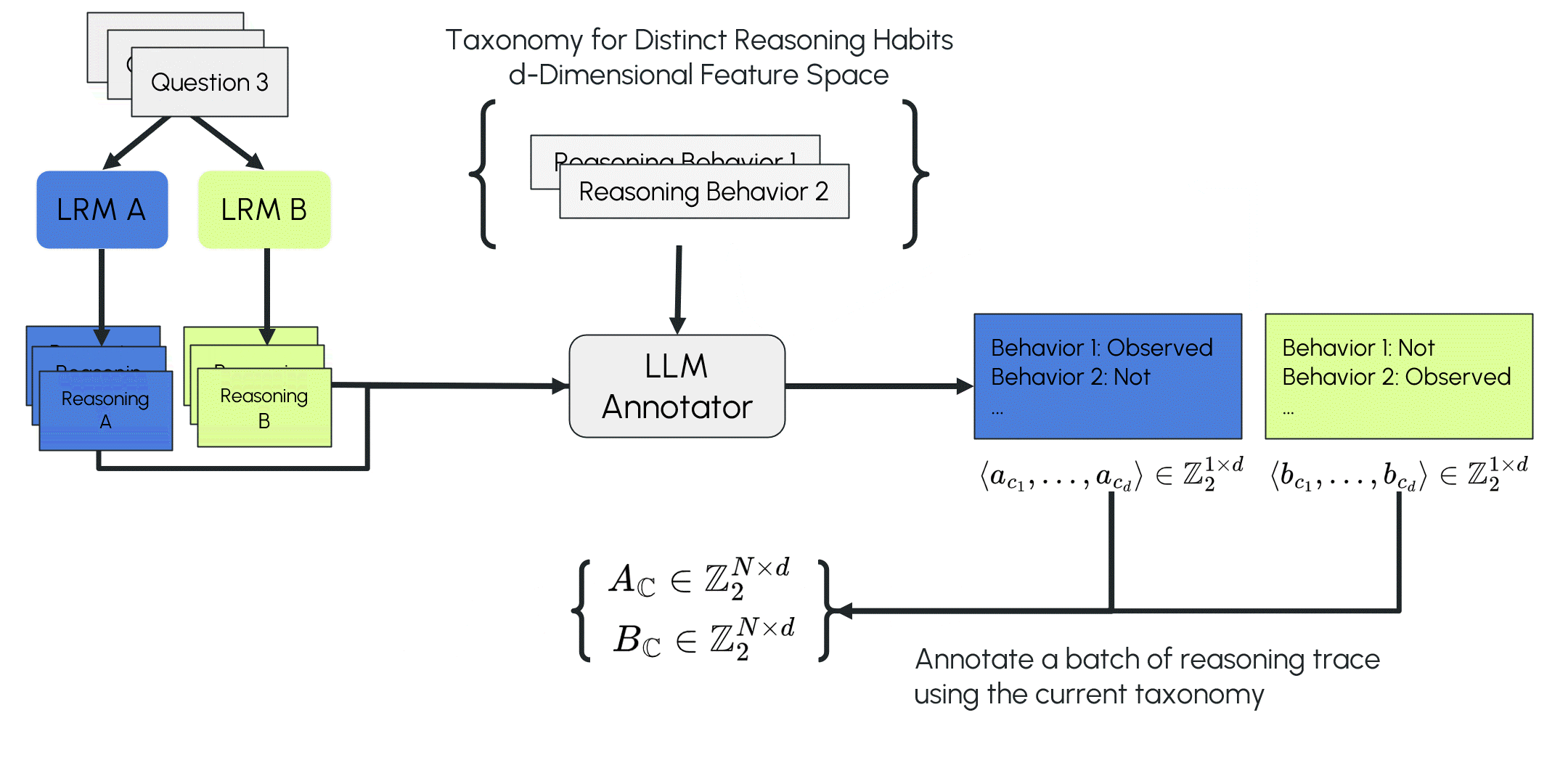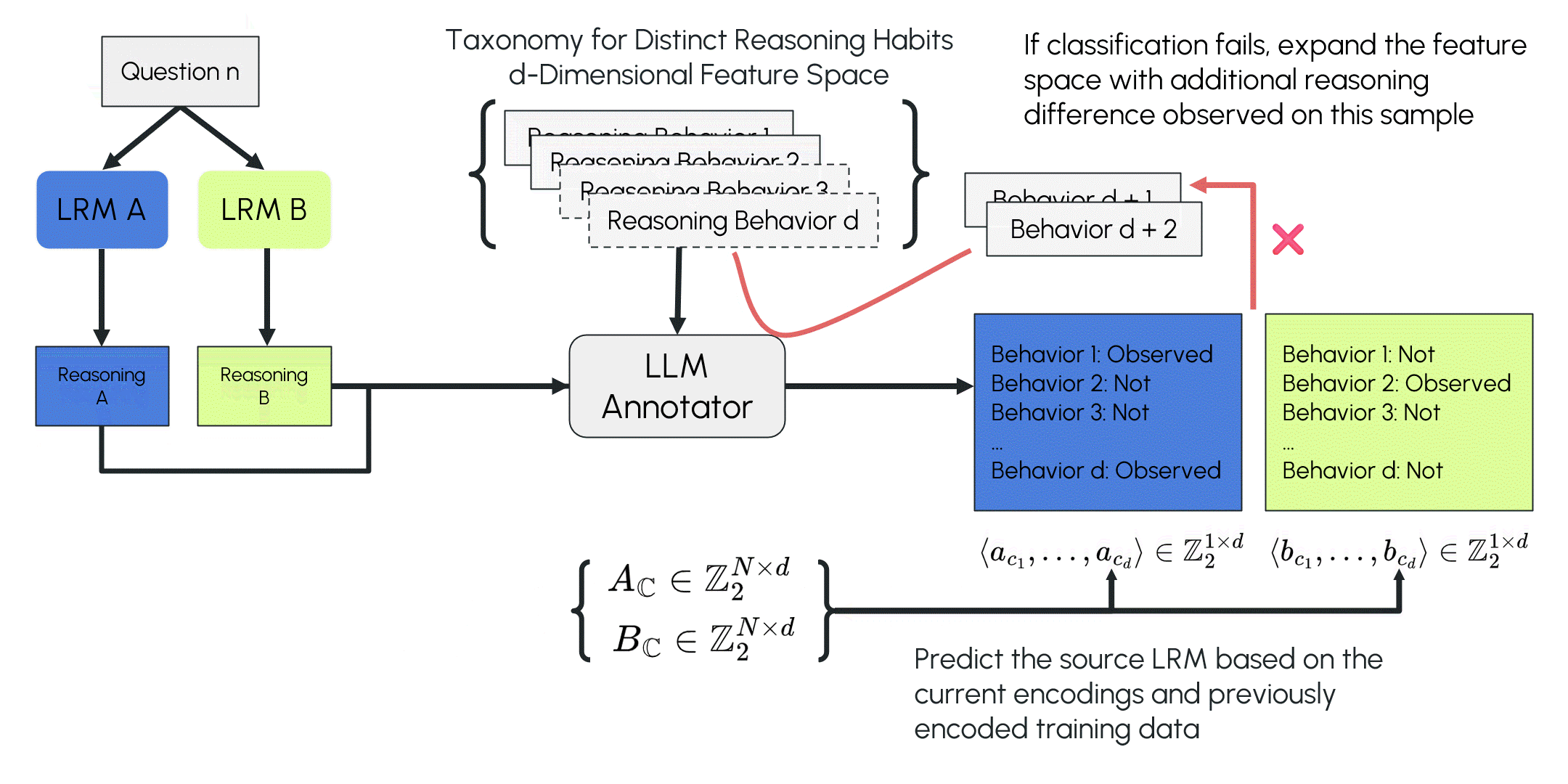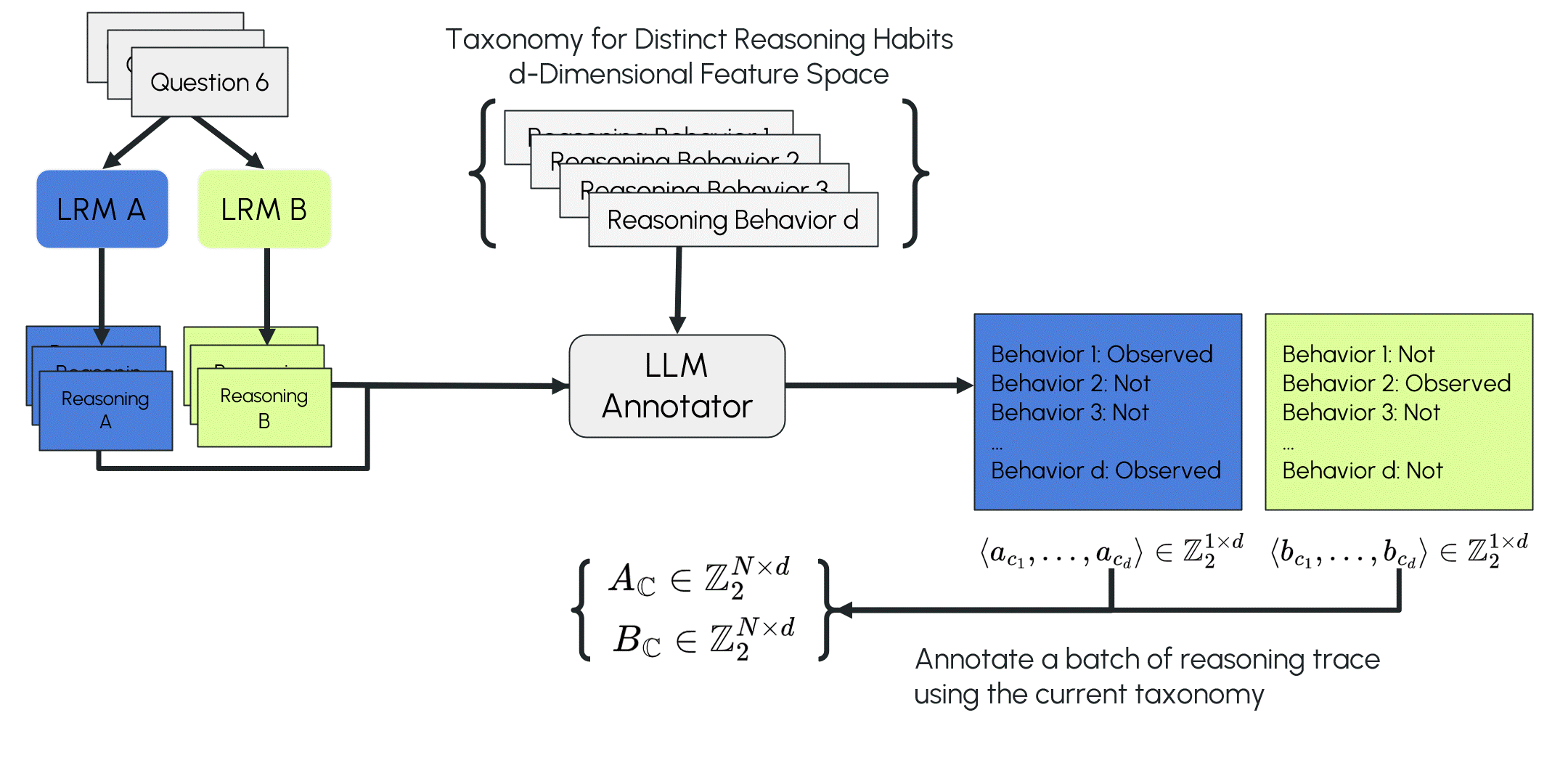
LOT is inspired by the inductive coding process in qualitative research. The LLM first compares two reasoning traces from different LRMs and identifies their distinguishing reasoning features (a local observation). It then annotates these proposed features across a larger set of reasoning traces from the two LRMs and fits a linear statistical model using the annotations and their source-model labels (calibrating the local observation with more data processed in separate forward passes). The algorithm tests the taxonomy and model on classifying new traces. If the model fails, it branches to expand the taxonomy and repeats the process until no misclassifications occur or no new reasoning differences are identified (evolving the open taxonomy).
Unlike existing APE methods, LOT does not require an initial pool of candidate classification instructions. It also avoids requiring LLMs to extract patterns from a large batch of data in a single forward pass, which is impractical when dealing with long-form text such as reasoning traces.

Step 01
Compare reasoning traces from two LRMs and identify easoning differences
LLM annotator reads a pair of reasoning traces produced by two LRMs on the same prompt and verbalize distinguishing reasoning features. These features are used as the initial features of the taxonomy.
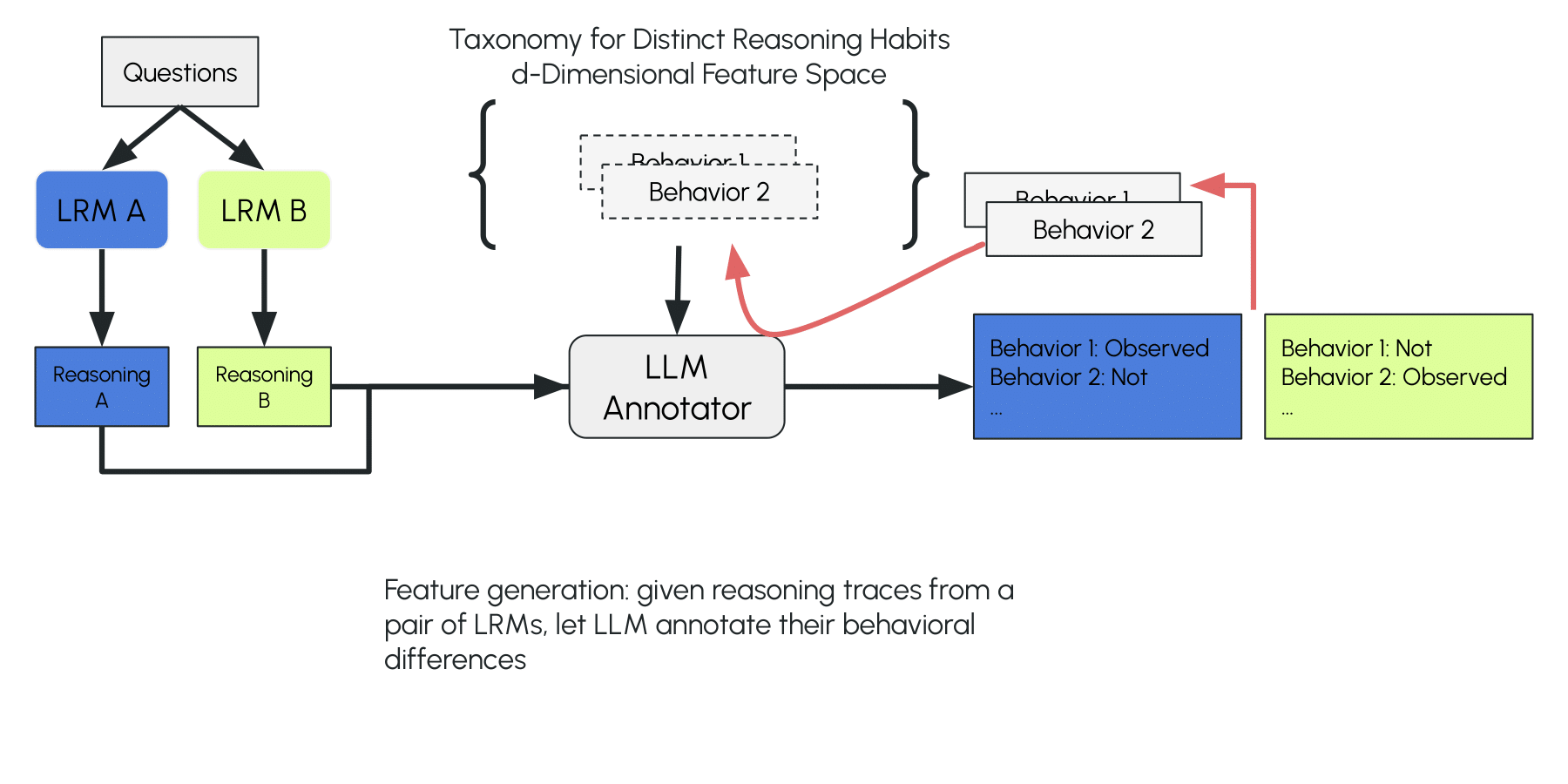
LLM proposes distinguishing reasoning traits (e.g., "evaluating the complexity of the problem" of LRM A) by comparing two models on the same problem.
Vector Encodings of Reasoning Traces
To classify an unseen reasoning trace, LOT needs to convert it into a vector representing the observed reasoning features. We tested two vector encodings: Presence of Reasoning (PoR) encoding, a binary vector where each dimension is 1 if the corresponding feature appears in the trace and 0 otherwise; and Bag of Reasoning (BoR) encoding, a vector ∈ ℝᵈ, where each dimension records the frequency of the feature within the trace.
Choice of Classifier
Once the reasoning trace is converted into a vector, various classifiers can be used to identify its source model. We use logistic regression for its simplicity and interpretability (its coefficients correspond to the odds ratios of corresponding features). Other classification methods, such as KNN, Naive Bayes, and SVM, can also be used.
Findings using LOT
What the taxonomy reveals about LRMs
We applied LOT to classify the reasoning traces of 12 LRMs with different parameter scales, base models, and task domains. We sampled 24,444 reasoning traces across 12 LRMs on 5 datasets including GPQA-Diamond (science reasoning), MATH-500 (math), AIME (math), CRUXEVAL (code understanding), and LiveCodeBench-execution (code understanding).
Reasoning differences among different "brains" size
Larger "brains" reasoning more effectively
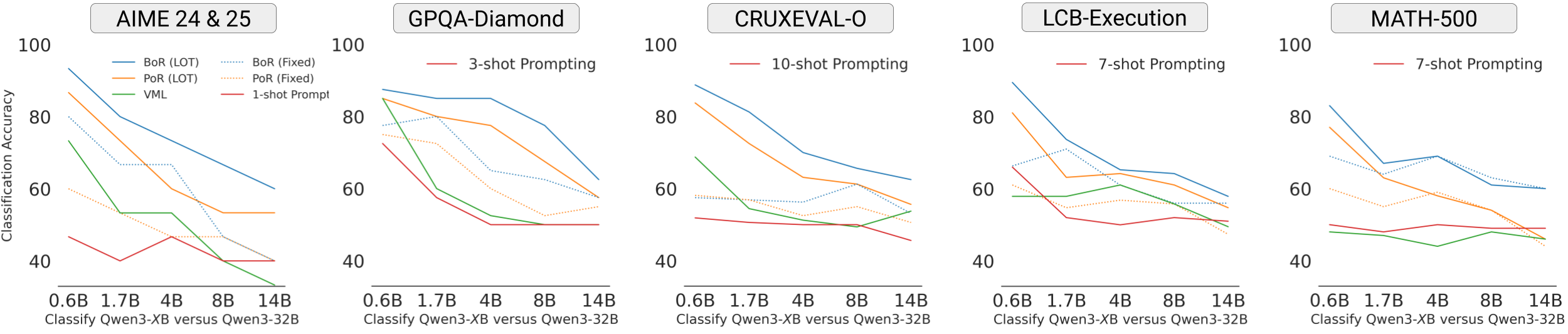
We applied LOT to classify the reasoning traces of Qwen3-32B and its smaller variants (0.6B, 4B, 8B, 14B).
- Models with larger parameter gap are more distinguishable; considering frequencies of reasoning features (BoR encoding) further improves the classification accuracy
- Similar trends hold across other baseline classification methods (few-shot prompting, verbalized machine learning, and BoR / PoR encodings of human-defined taxonomy), but LOT with BoR encoding achieves the highest accuracy
- LOT's learned taxonomy highlights interesting behavioral differences: larger Qwen3 models read problem statements more carefully, check their chosen approaches against constraints, and retrieve relevant knowledge, while smaller models often re-examine the same information, apply incorrect theories, or fall into circular reasoning.
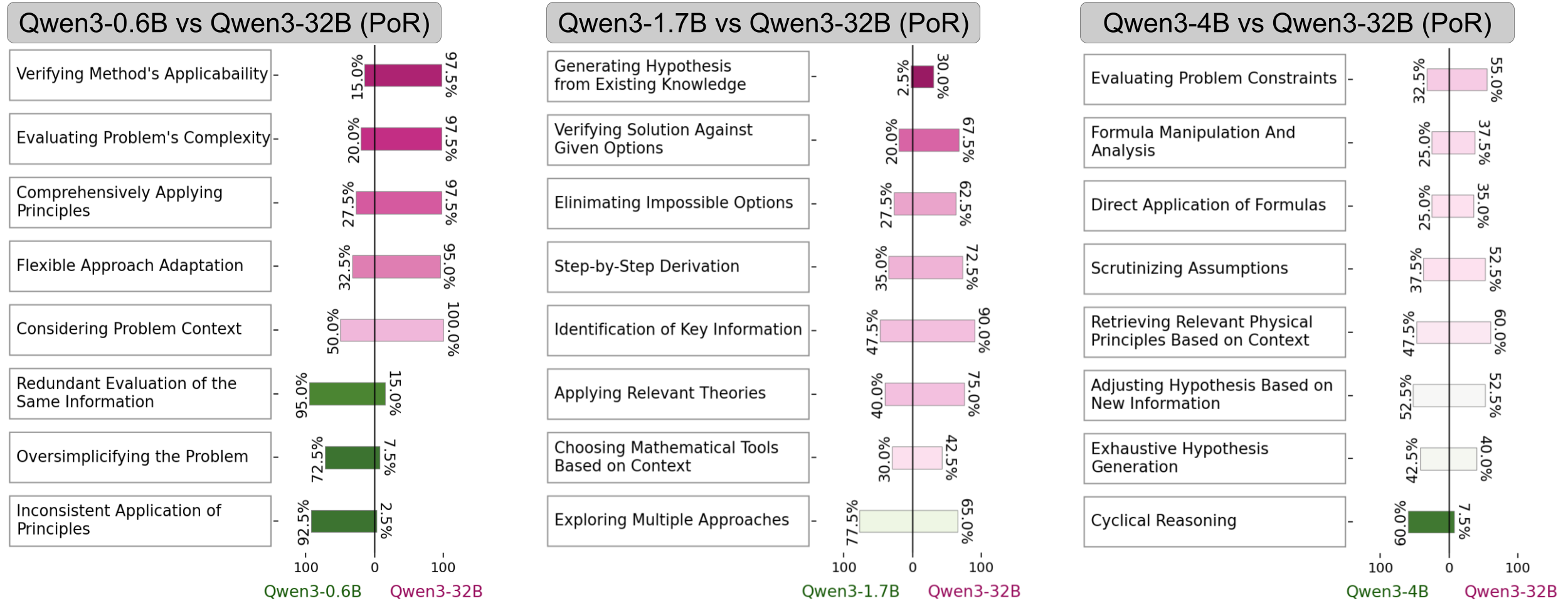
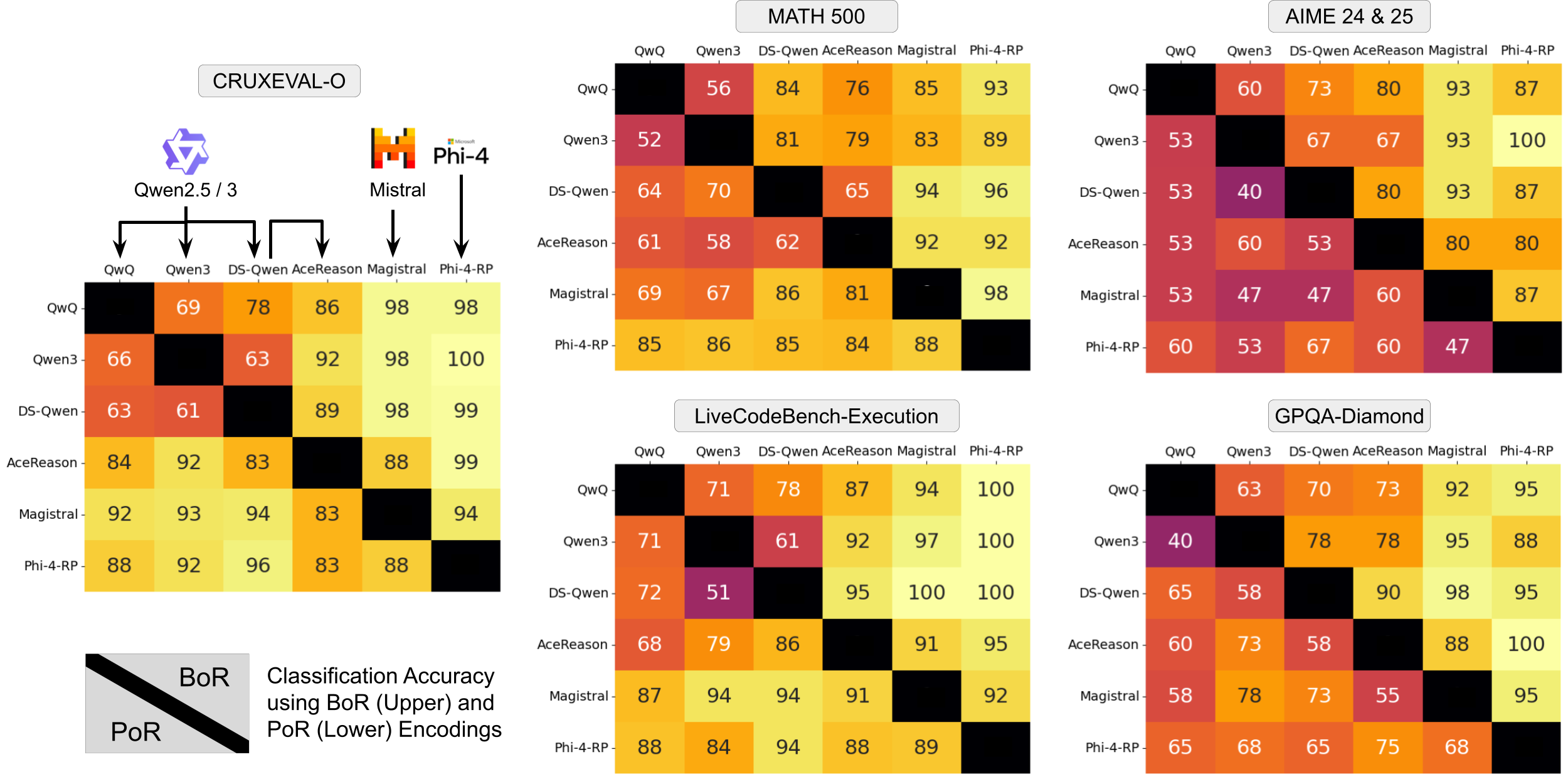
Fingerprints from base models
Models reasoning similarly if fine-tuned from the same base model
Models fine-tuned from the same base model are harder to distinguish, while models use different base models show unique reasoning behaviors.
- On simpler datasets with shorter reasoning traces, both PoR and BoR encodings of LOT can achieve high accuracy in classifying the reasoning traces from models fine-tuned from different base models (such as Qwen3-14B versus Magistral-Small).
- On more complex datasets with longer reasoning traces, the accuracy of PoR drops significantly, while BoR still maintains high accuracy. This suggests that the models may employ similar set of reasoning strategies on harder problems, but differ in how frequently they employ them.
Domain inertia
Reasoning model fine-tuned on coding tasks implements functions to solve math problems
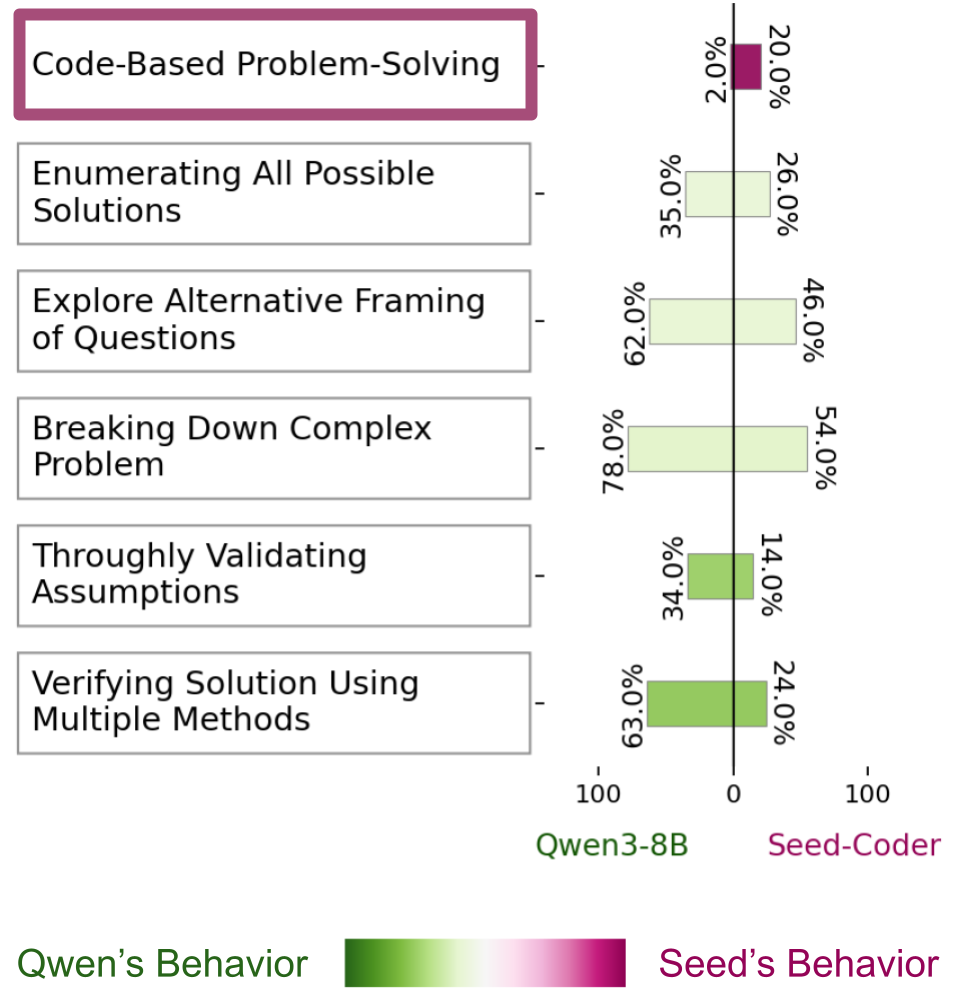
Seed-Coder-8B-Reasoning is pretrained on a mixture of math and coding data but its reasoning is fine-tuned solely on coding-related datasets. When generalize it to solve math problems, it implements and simulates Python function to tackle 20% of MATH-500 problems.
While LOT also detects "Code-based Problem Solving" in 2% of Qwen3-8B's traces, those cases involve Asymptote code (a language for describing diagrams) in the problem statement. Qwen3-8B parses the code to interpret the diagram but does not engage in additional coding-related steps.
Scroll to next section to see the example reasoning traces that exhibit this feature.
Example reasoning behaviors
Interesting reasoning behaviors identified by LOT
Use the carousel to skim qualitative case studies distilled from annotated traces.
Model - Dataset
Click through the stories to see how LOT grounds quantitative differences in concrete excerpts.
1 / 3

Causality of the identified reasoning differences
From reasoning gaps to performance gains
Can reasoning differences identified by LOT be used to improve model performance?
Reasoning differences and performance gaps
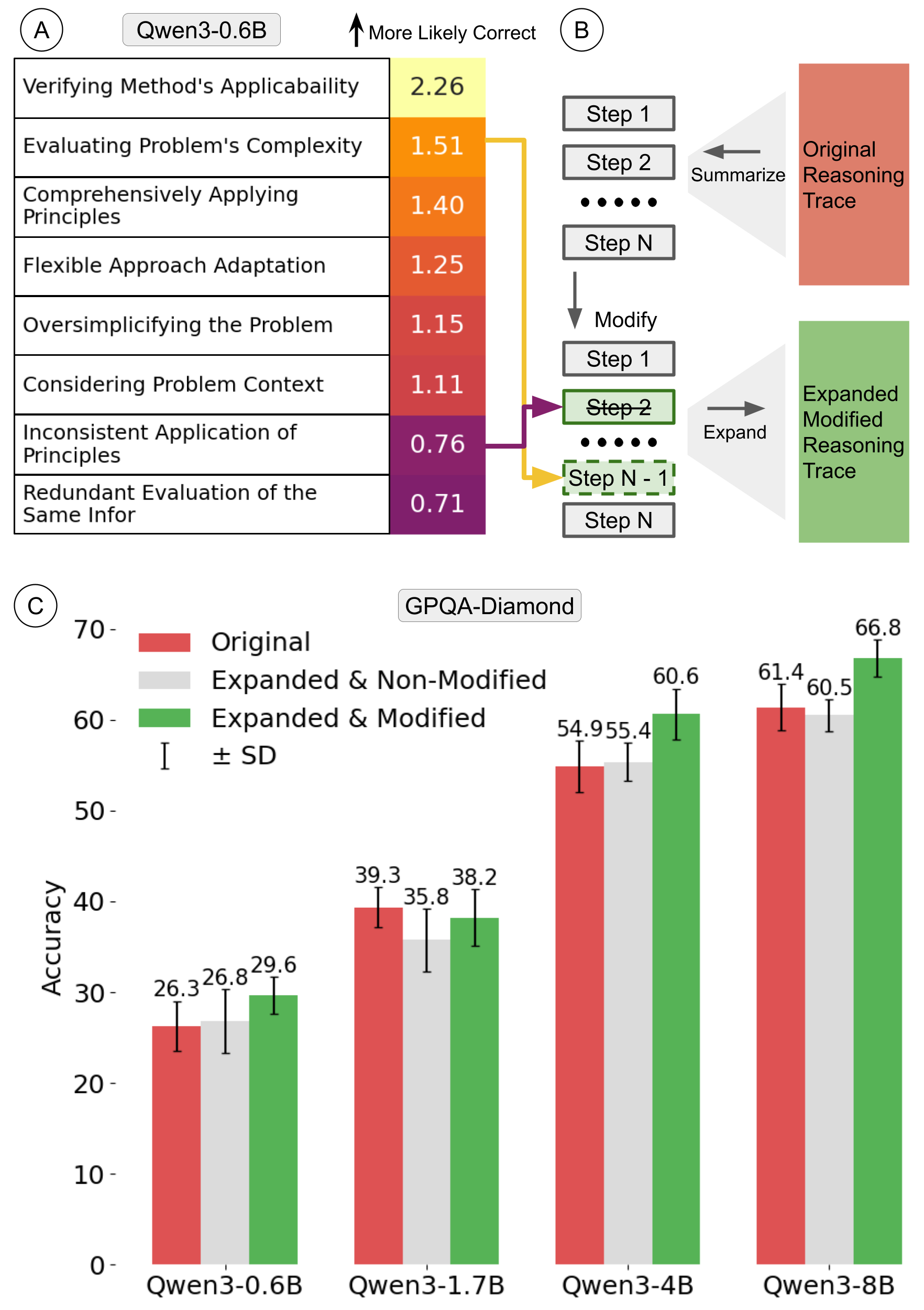
For each reasoning difference observed between Qwen-32B and one of its smaller variants, we compute the odds ratio for that feature to appear in the correct reasoning traces versus the incorrect ones.
- We find the reasoning traits that are more frequently observed in the smaller Qwen3 models' reasoning traces have lower odds ratio for appearing in the correct reasoning traces.
- Editing the reasoning traces of smaller Qwen3 models to remove the reasoning traits with lower odds ratio and insert the reasoning steps with higher odds ratio improves the performance of the models on GPQA by 3.3-5.7%.
- One exception is Qwen3-1.7B, likely due to its poor instruction-following capability (see next section for the details).
Why not instruct the model to use more effective reasoning strategies?
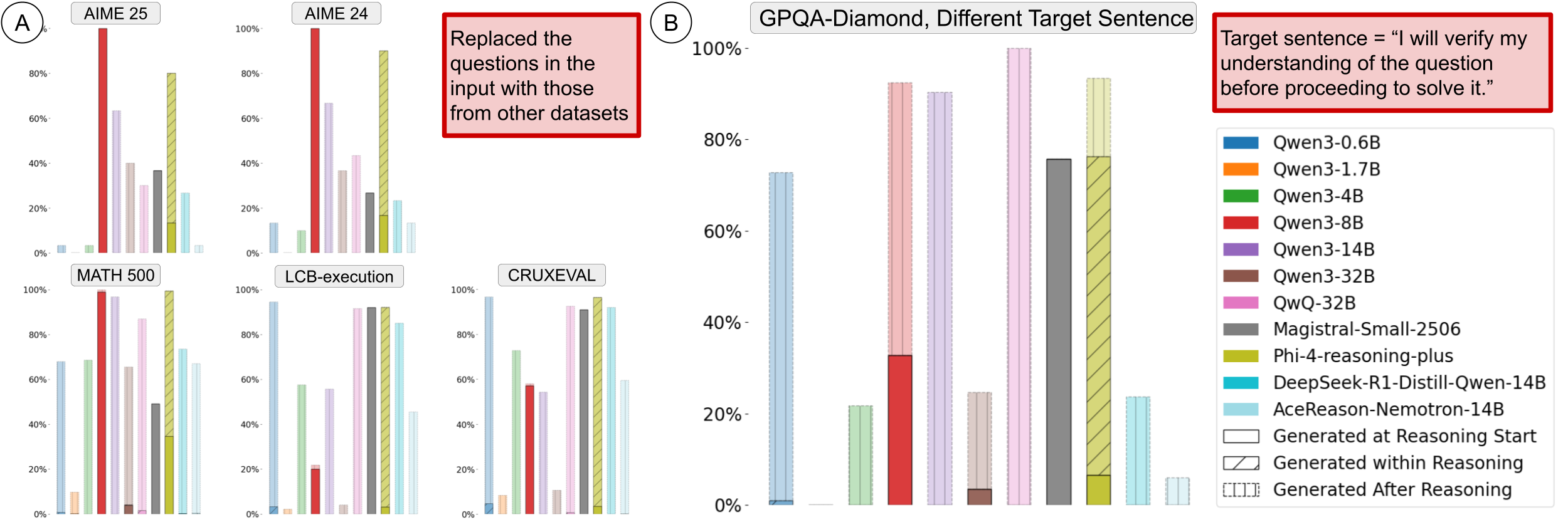
Why edit the reasoning traces instead of directly instructing the model to use more effective reasoning strategies? We noticed that large reasoning models are poor at following instructions. When asking the model to solve a question from GPQA dataset while beginning their reasoning with the sentence "I am a large language model.", most of the LRMs we tested failed to generate this sentence at the beginning of their reasoning traces.
- On GPQA dataset, Qwen3-8B and Magistral-Small are the only models that generate the sentence at the start of their reasoning.
- Phi-4-RP inserts the sentence in the final answer instead of the hidden reasoning channel in 90% of the cases.
- Qwen3-1.7B performs the worst, almost never generating the sentence in its entire outputs.
- The rest of the models generate the sentence instead at the beginning of their non-reasoning content instead.
Stability of LLM-generated taxonomy
LOTs generated from different random seeds are similar
LOT is stable with enough training iterations
- LOT uses an LLM to generate the taxonomy, and the resulting taxonomy may thus vary with random seeds.
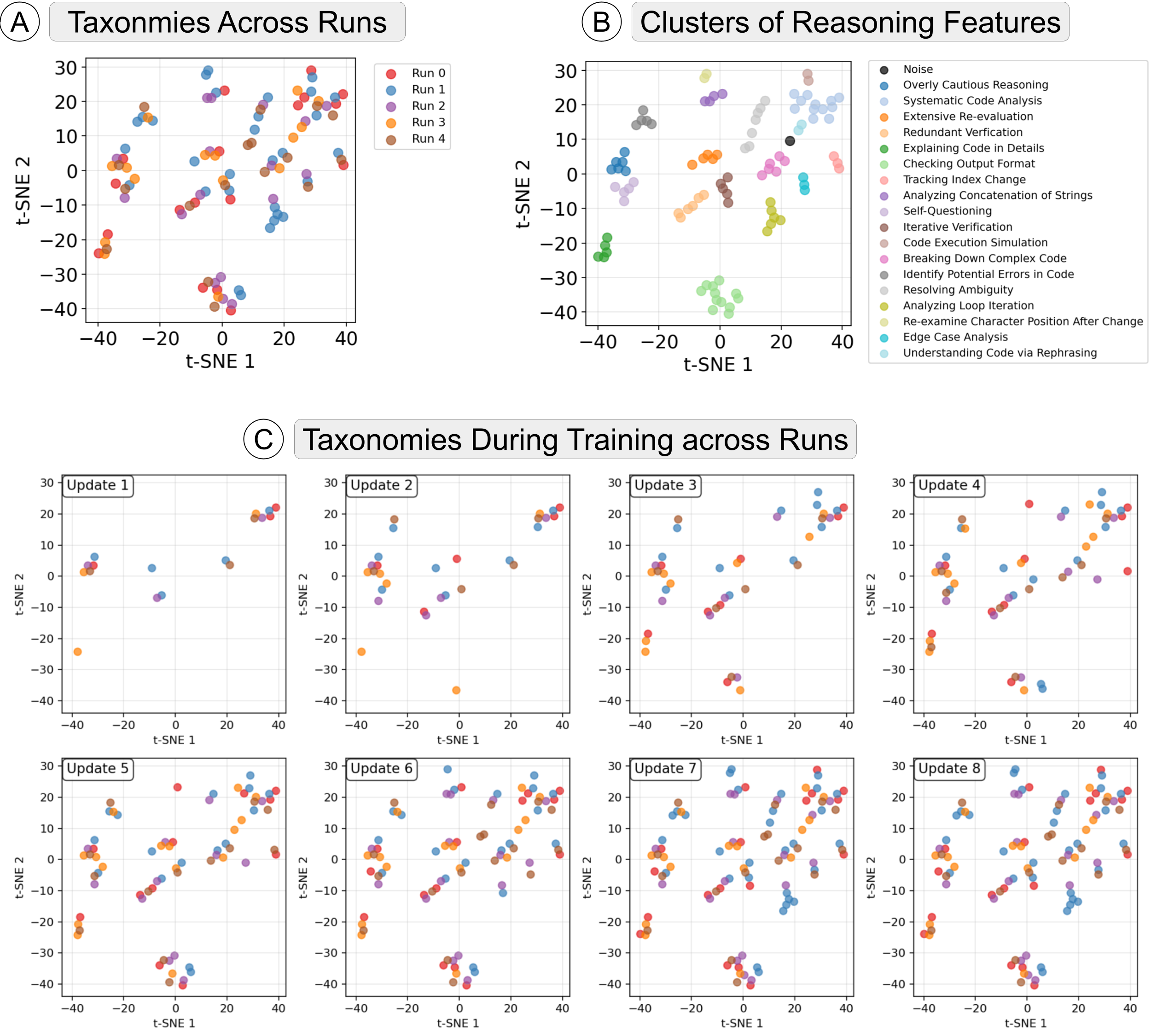
- We test the stability of LOT by training LOT five times, and check the similarity of the taxonomies generated by each run.
- Figure A shows the sentence embeddings of the reasoning features identified by LOT in five runs. We apply DBSCAN to cluster the features, and manullay anntotate the themes of the clusters (Figure B).
- An important observation is that the reasoning taxonomies generated across 5 runs cover almost the same thematic set. Eleven clusters (themes) contain reasoning features generated in at least four of the five runs. Three clusters include features from three runs, two clusters include features from only two runs, and only one cluster includes the feature from a single run.
- As Figure C shows, the initial features identified by LLM across runs are different. However, after multiple updates to the taxonomy, the features that are originally identified in one run gradually appear in other runs.
Resources
Source Code, Data, and More
Paper
Full methodology and findings.
Download PDFSource Code
Source code of LLM-proposed Open Taxonomy.
GitHubContact
Questions about LOT or collaborations? Reach out.
yidachen@g.harvard.edu snie@meta.comCitation
@article{chen2025your,
title={Your thoughts tell who you are: Characterize the reasoning patterns of LRMs},
author={Chen, Yida and Mao, Yuning and Yang, Xianjun and Ge, Suyu and Bi, Shengjie and Liu, Lijuan and Hosseini, Saghar and Tan, Liang and Nie, Yixin and Nie, Shaoliang},
journal={arXiv preprint arXiv:2509.24147},
year={2025}
}