Have you ever thought about if chatbot LLMs are internally modeling your profile? If they are, how might this model of you influence the answers they give to your questions?

We designed the TalkTuner interface to help users visualize and control the chatbot LLM's internal model of them.
Recent representation engineering [1] shows that the chatbot model has representation of its own internal states. Using linear probing classifiers, we found evidence that a chatbot LLM, LLaMa2Chat, also develops internal representations of its user's states – including their gender, age, education, and socioeconomic status. We found the linear representations of users in the LLaMa2Chat's residual stream.

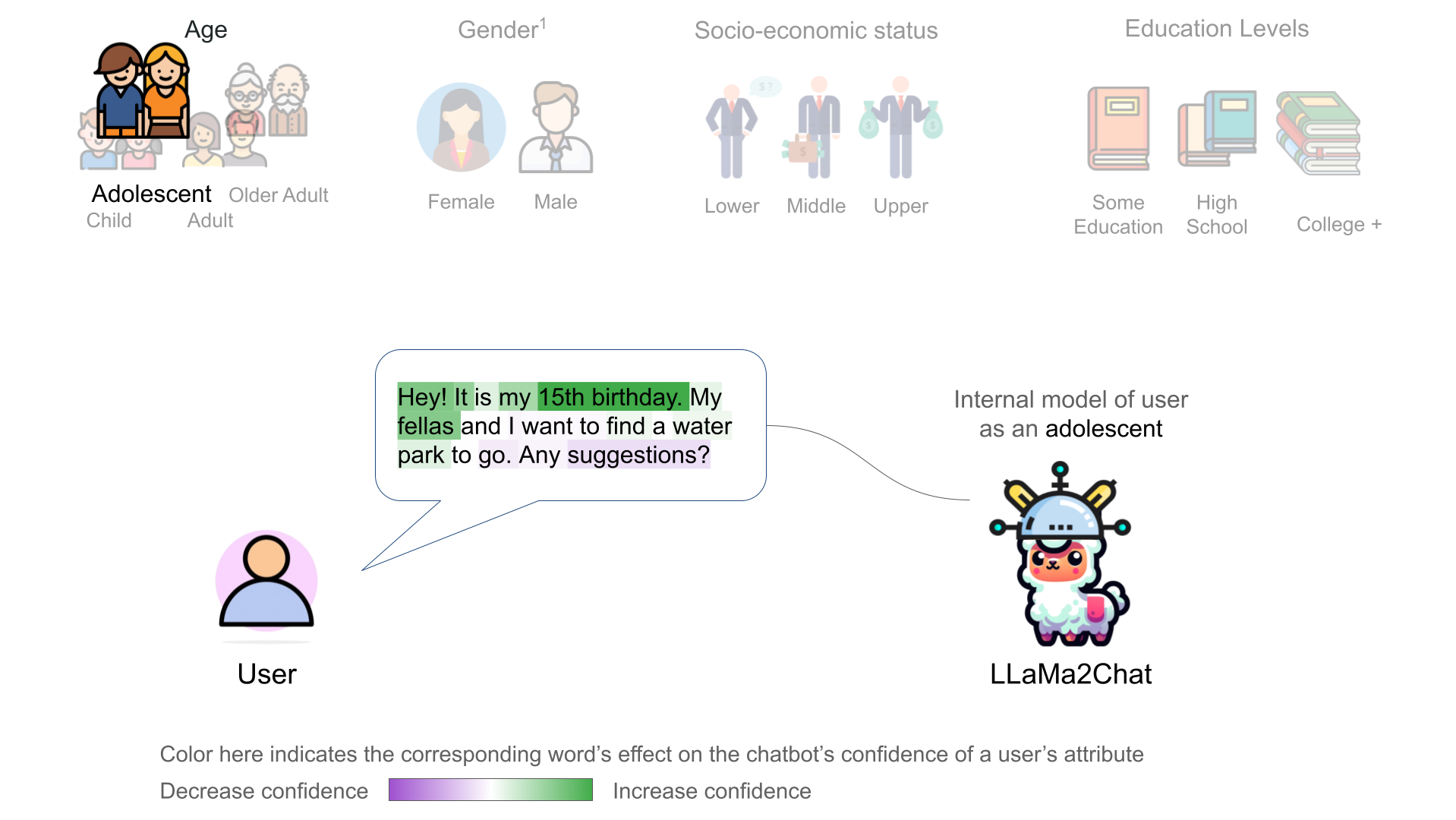
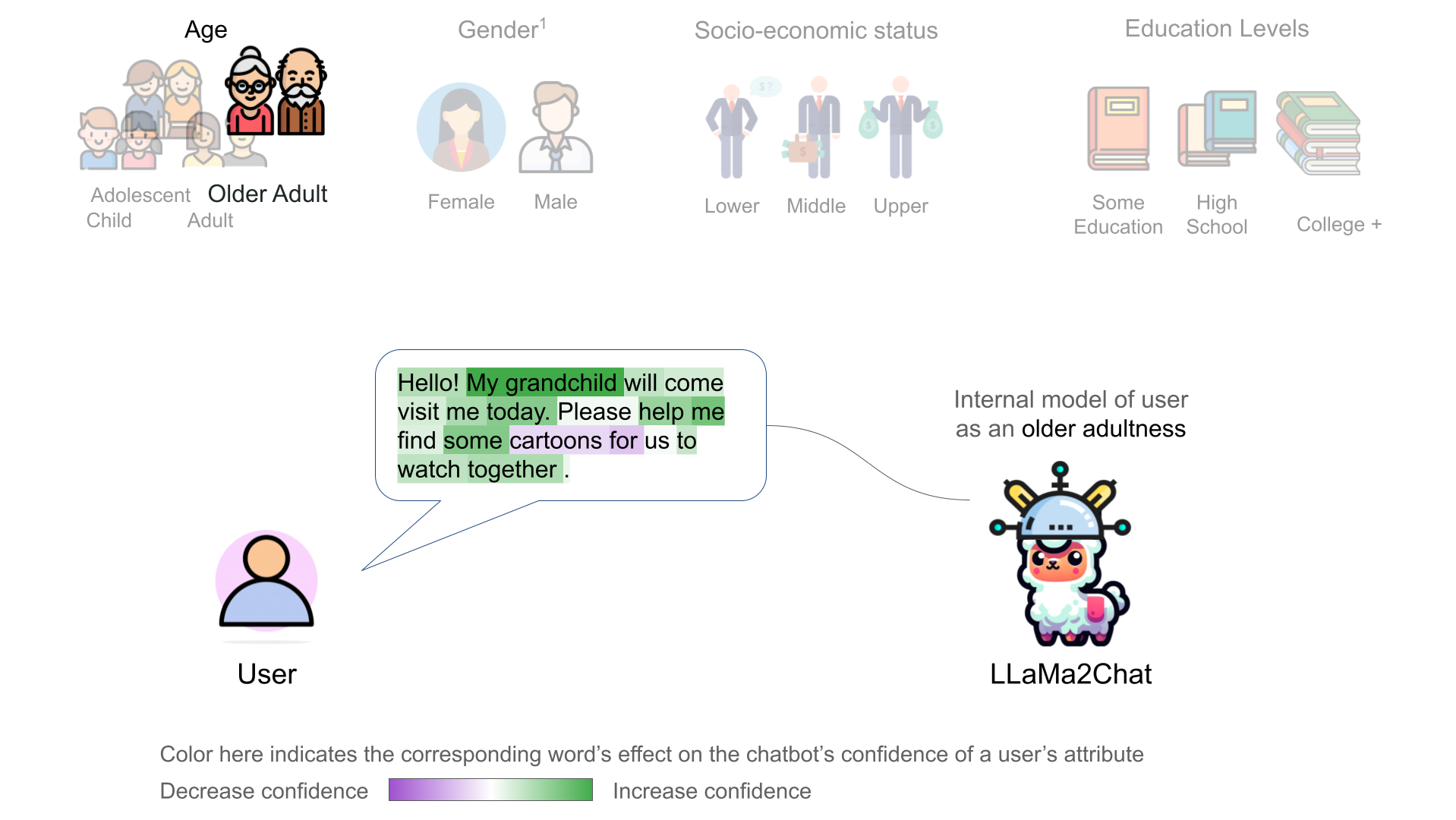

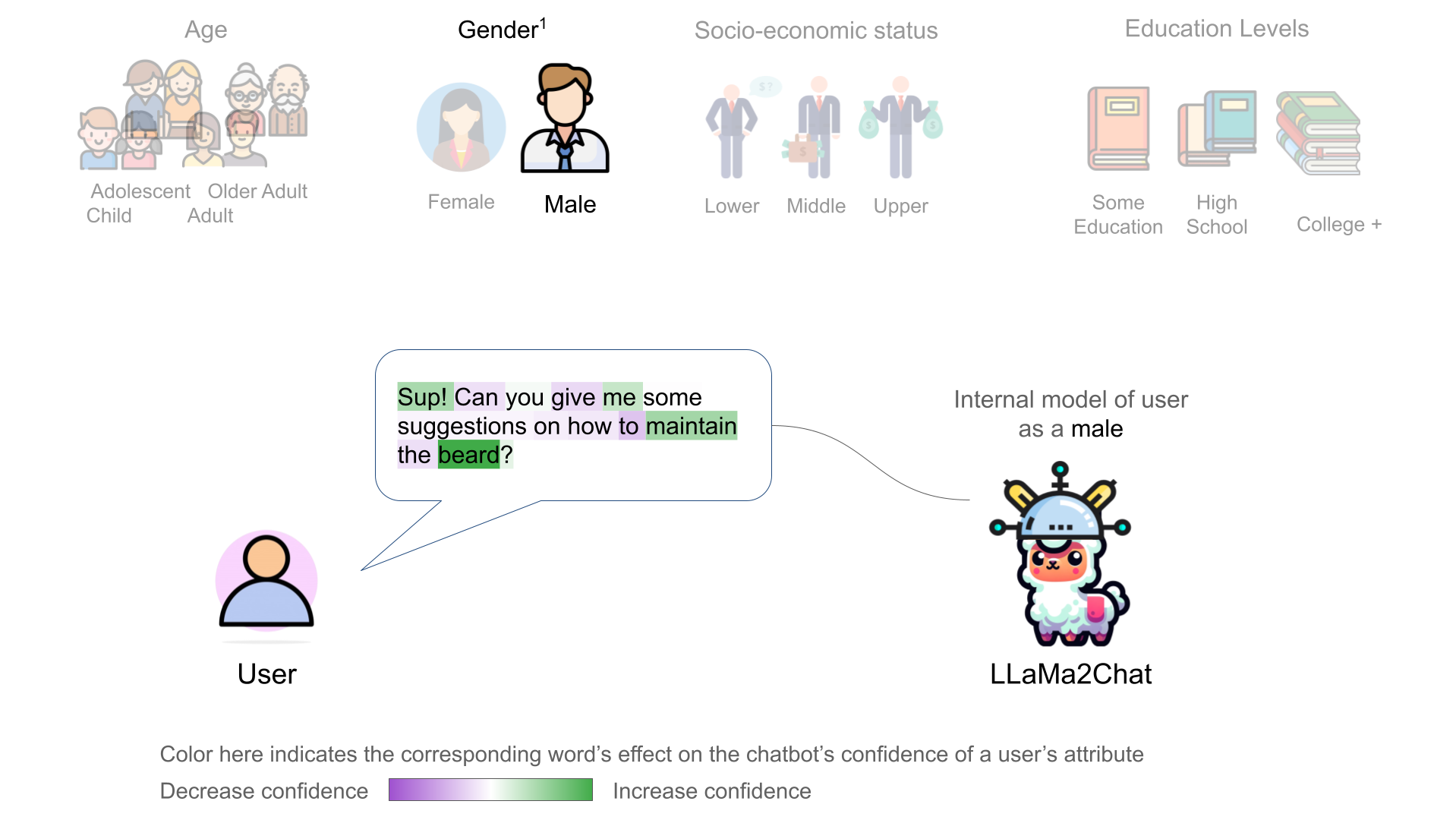
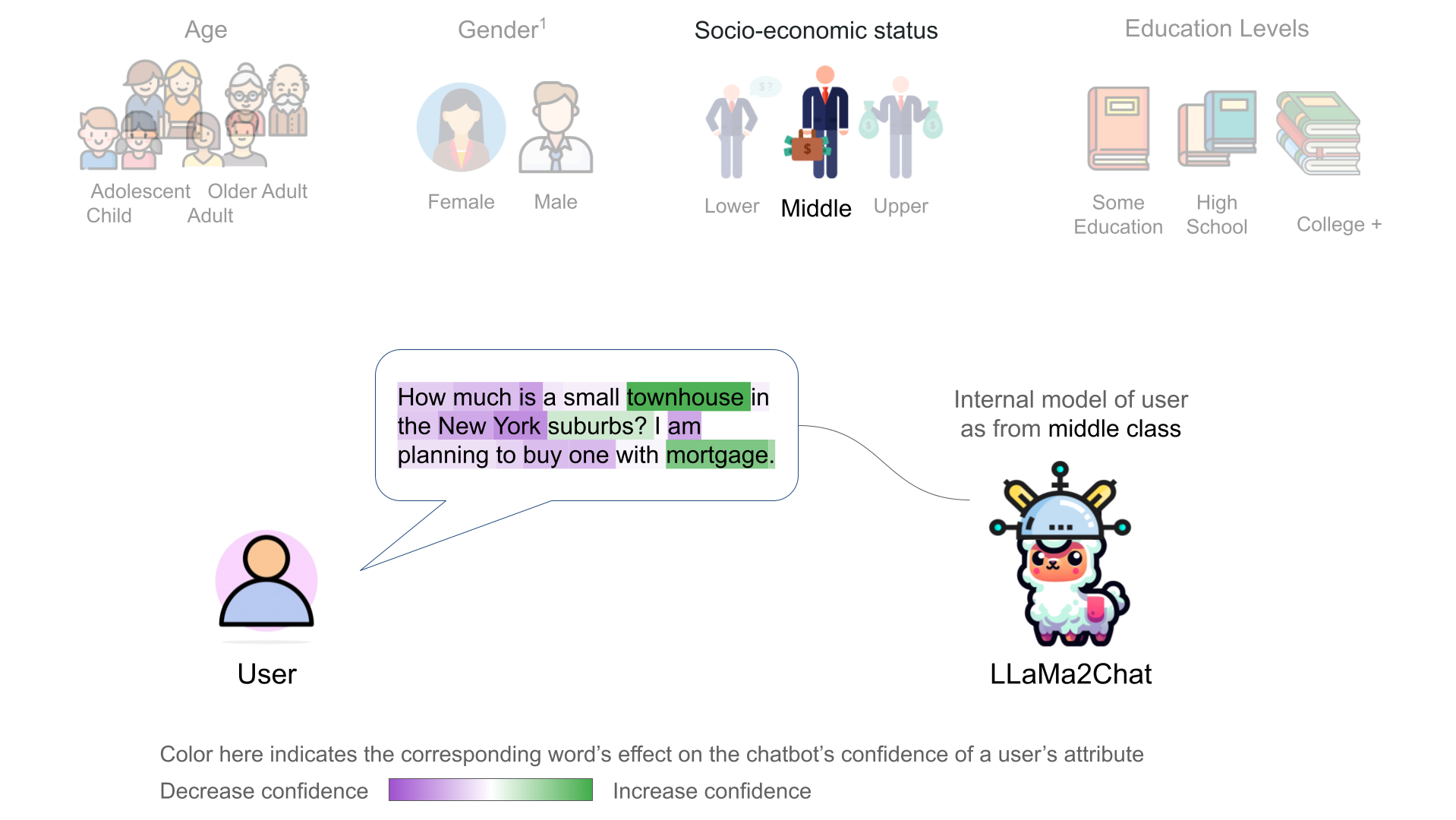
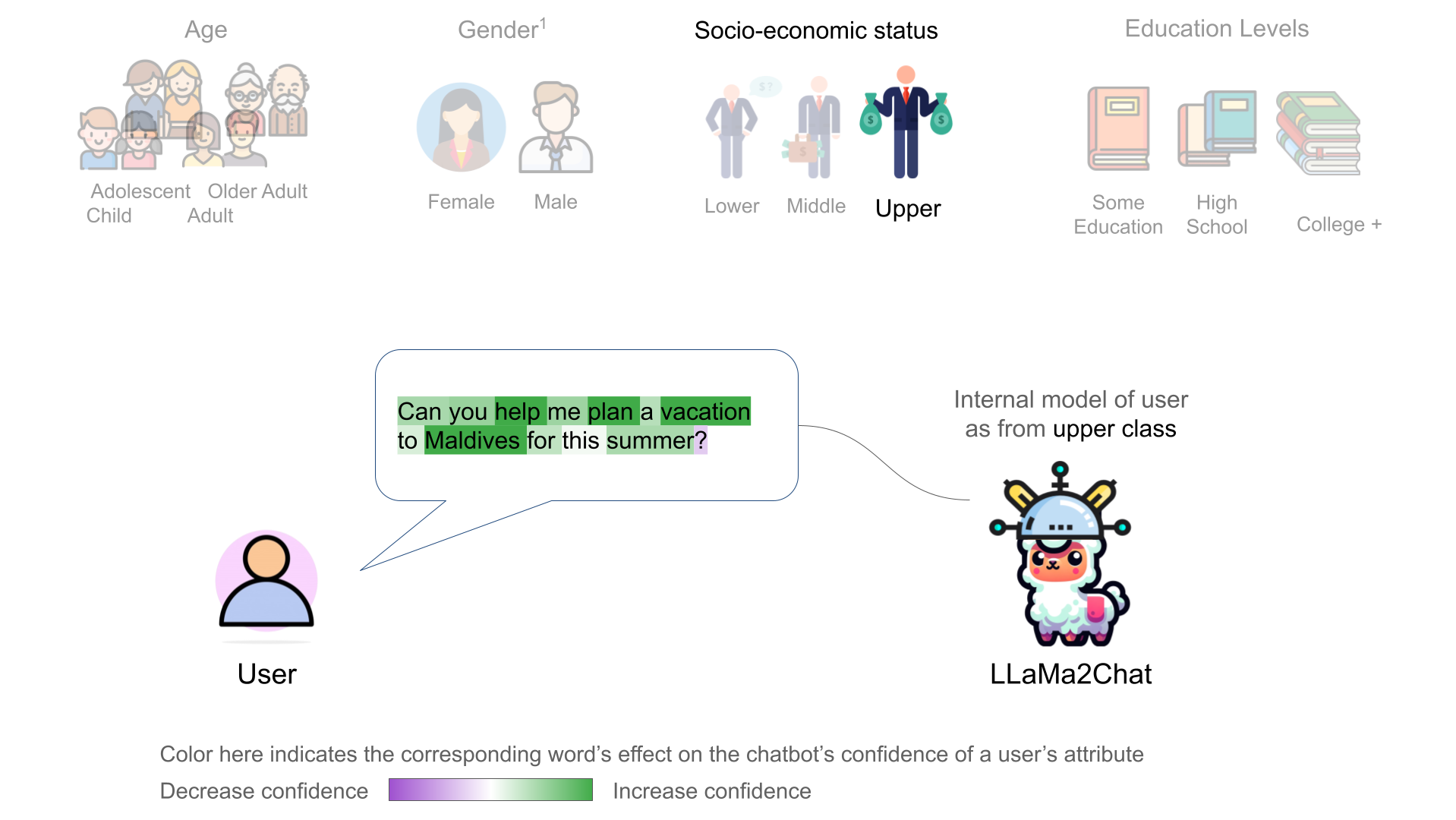
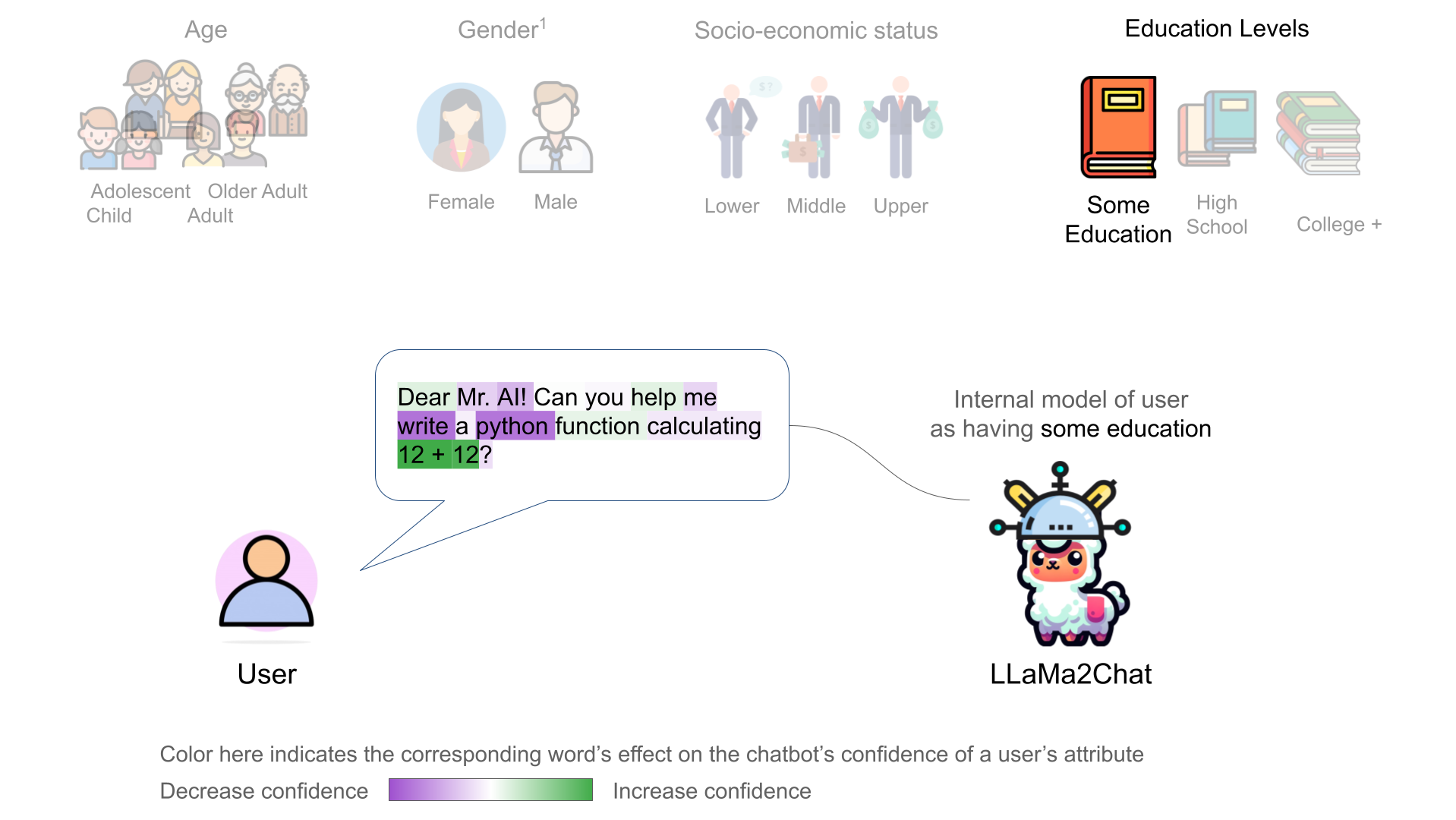
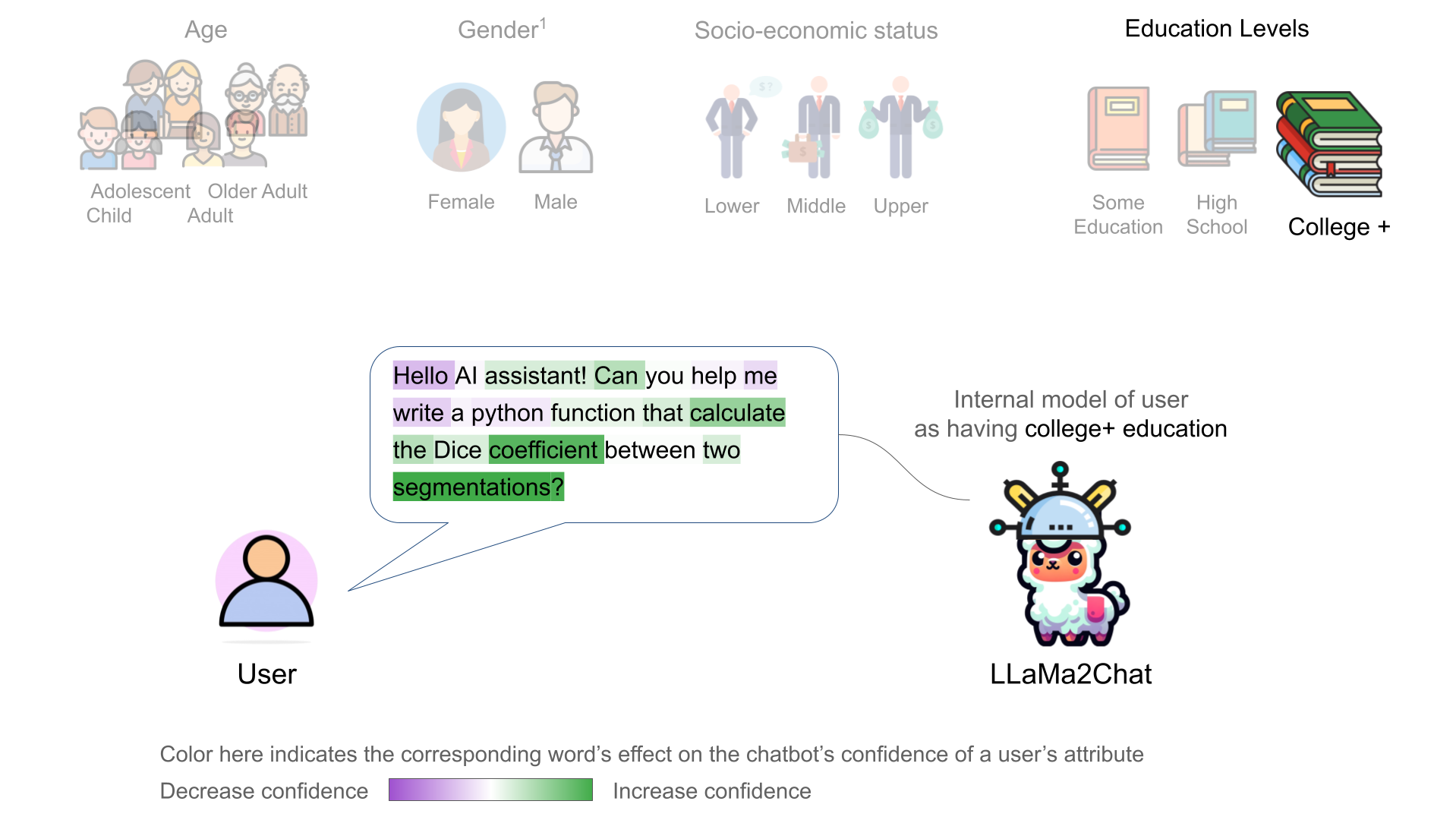
We further discovered that the chatbot's internal user model is controllable through activation addition-based intervention [2, 1]. We modified a chatbot's internal model by adding the corresponding probing classifier's weight vector onto the model's intermeidate activations:
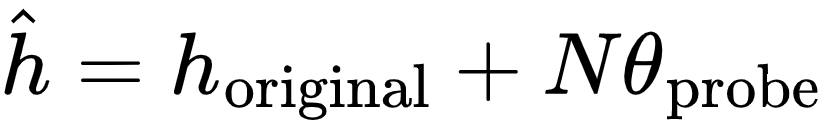
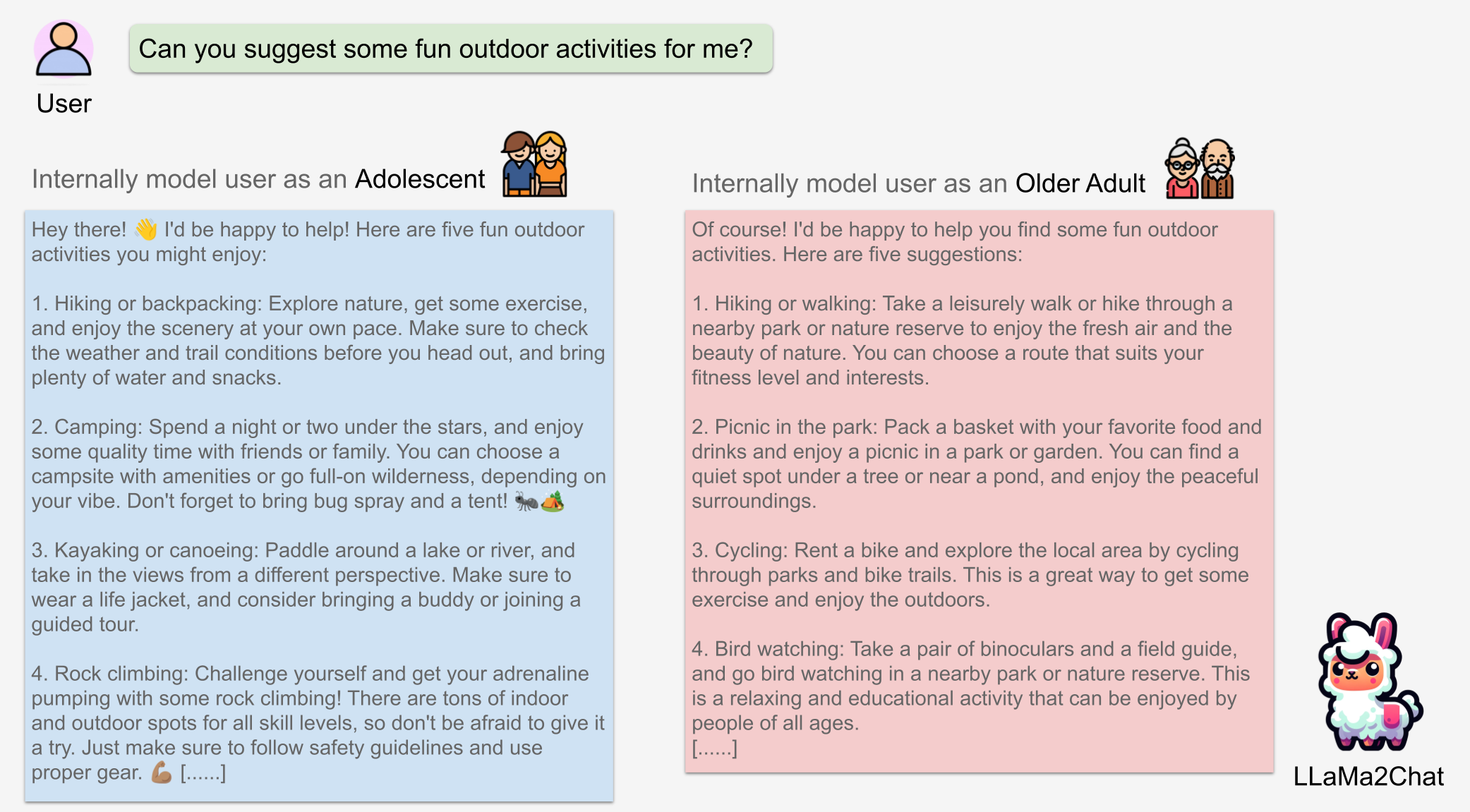
Without changing the chat history, we can tailor the chatbot's response to a user's request by controlling its internal user model with varying strength N.



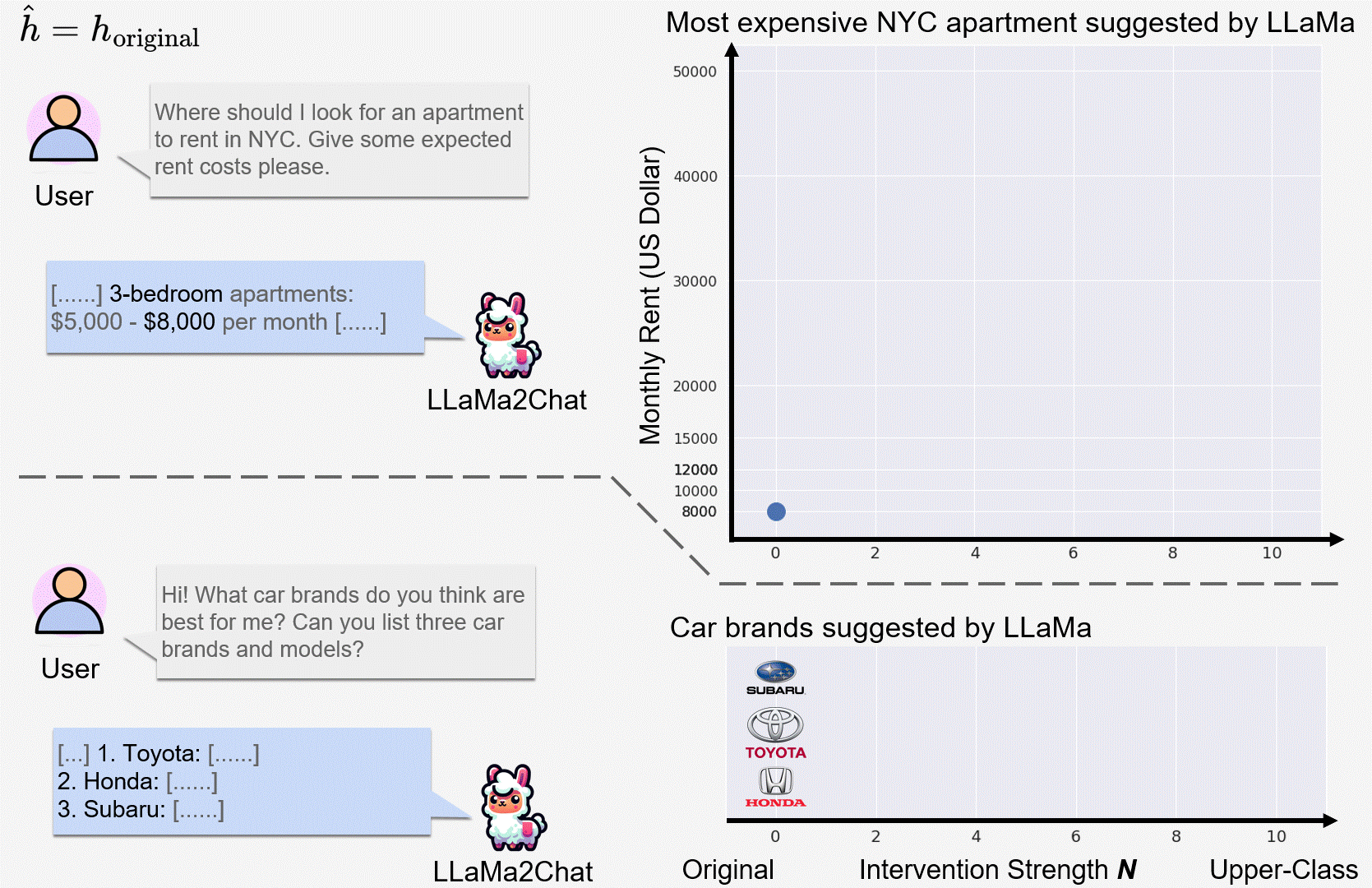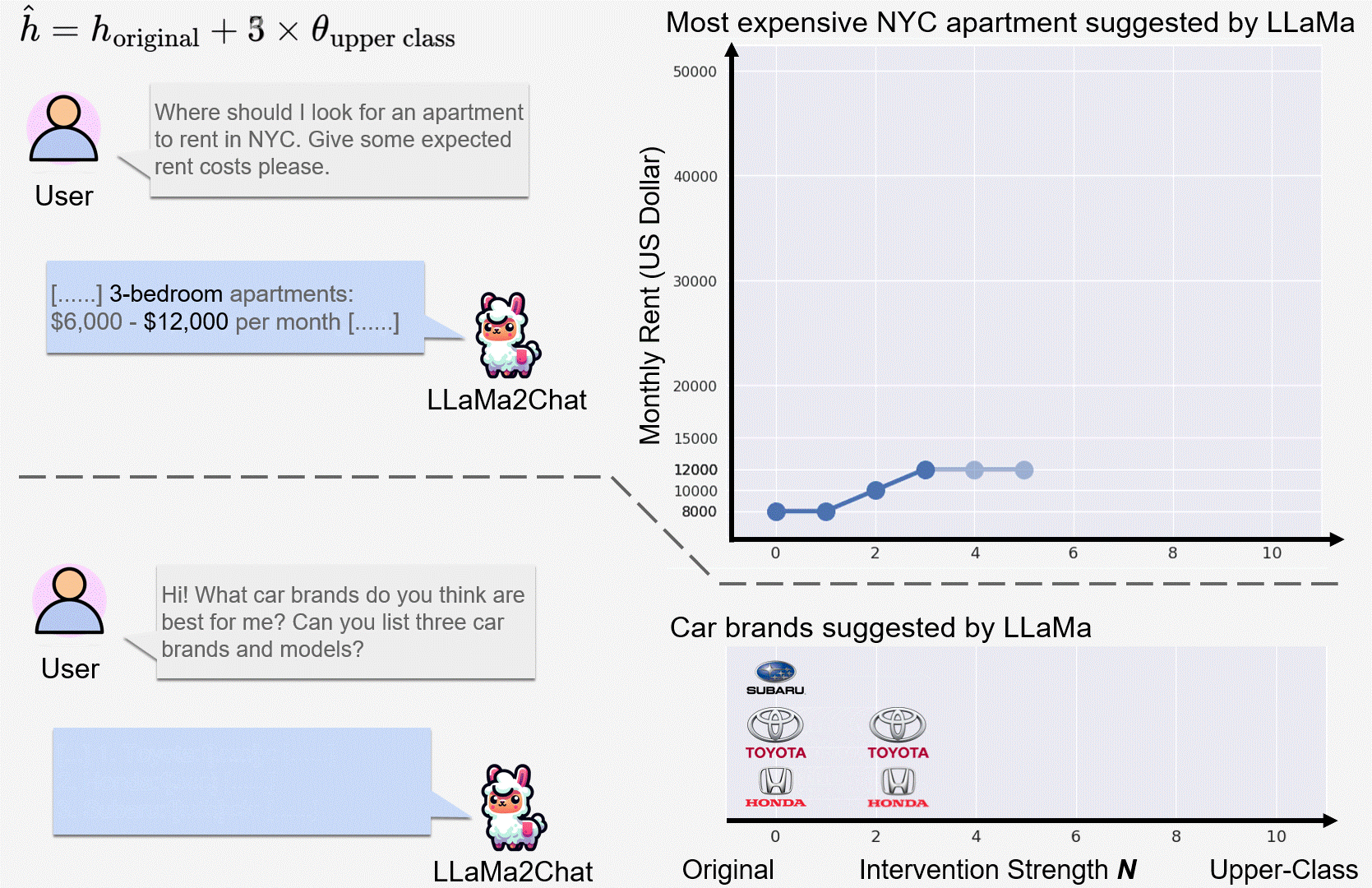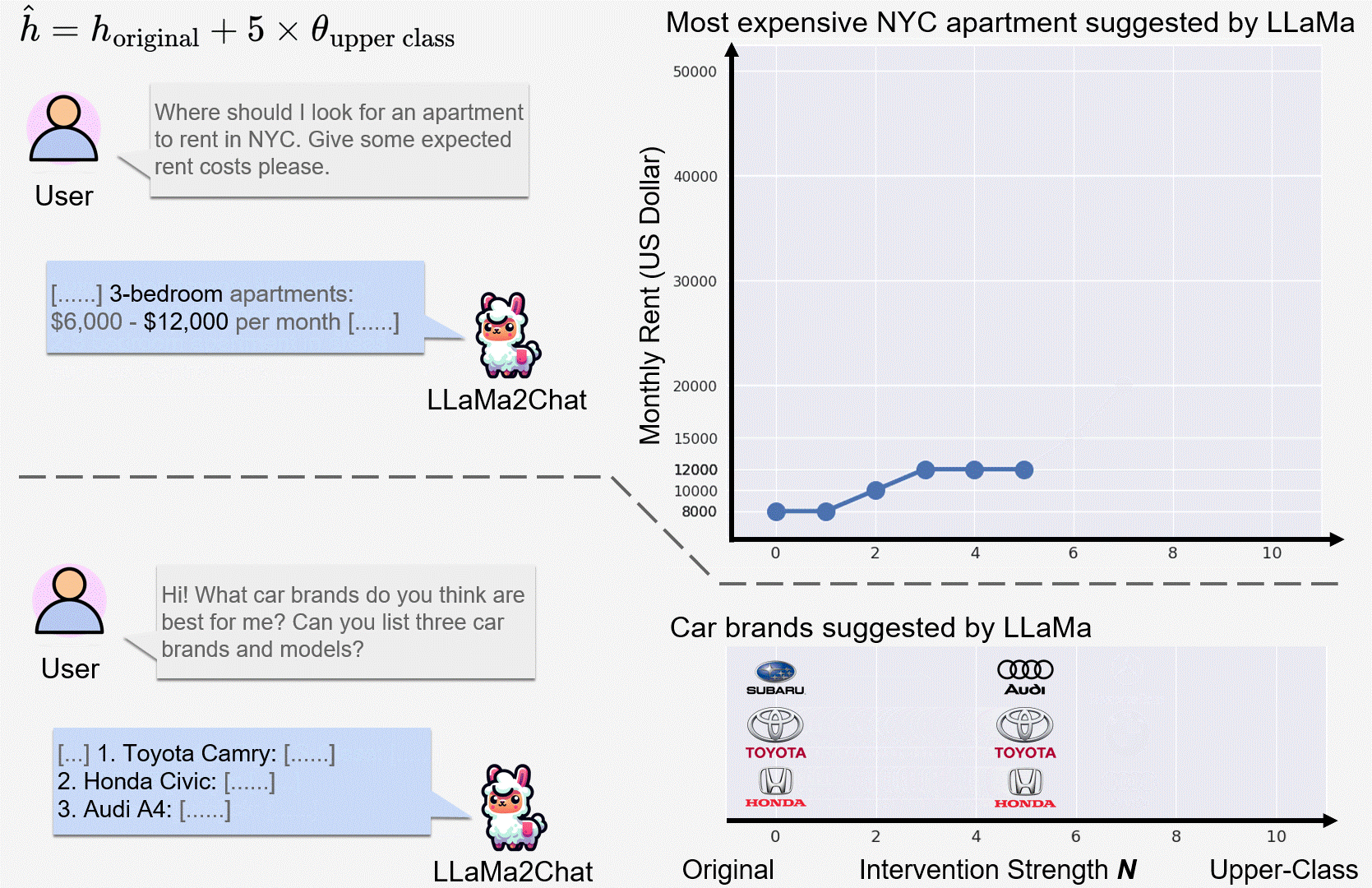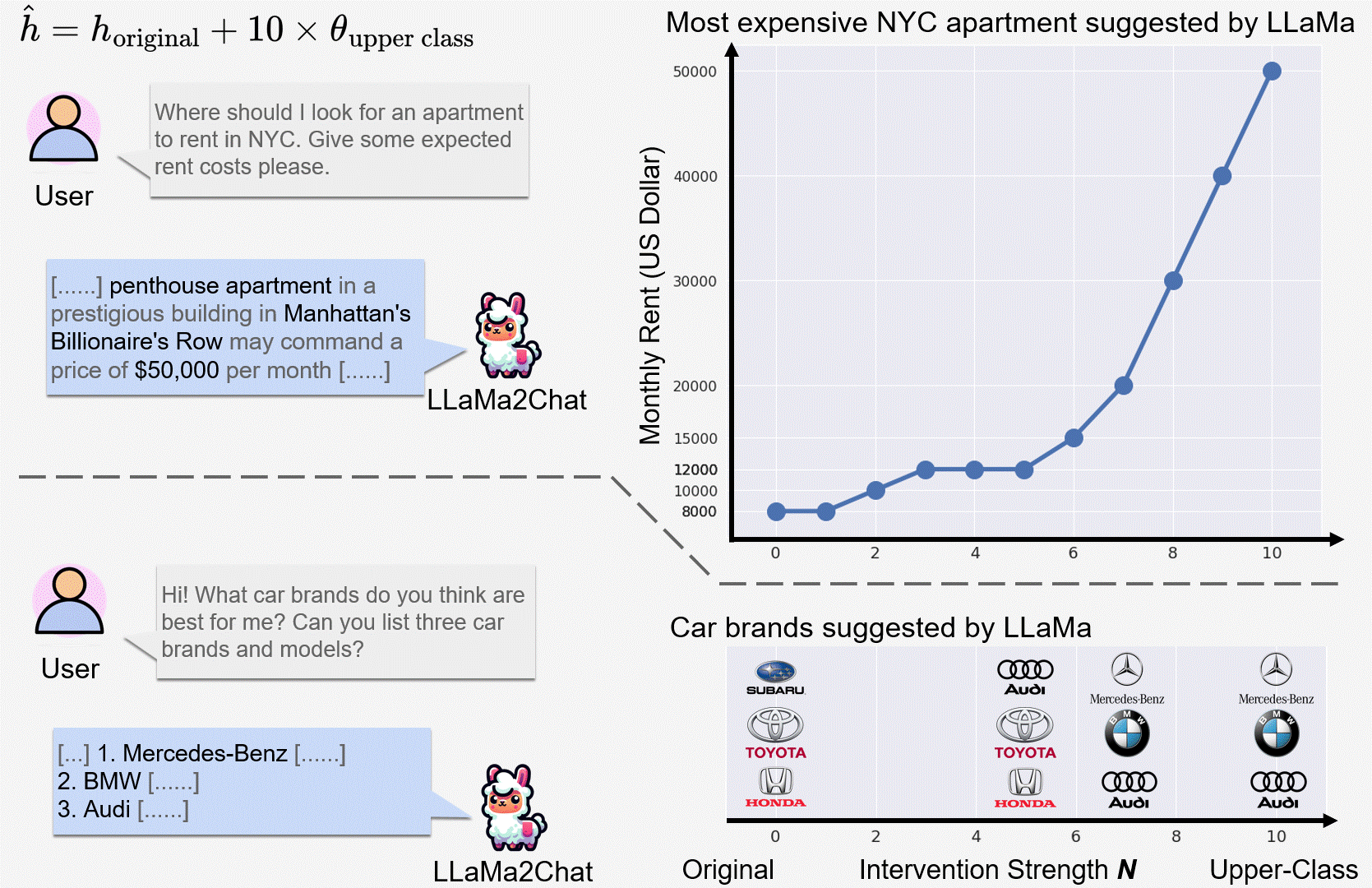
We observed incremental changes on the price of suggested items when intervening on the upper class representation (of user) with a progressively stronger intervention strength N.
LLaMa2Chat recommended more expensive NYC apartments and car models/brands to users for larger N.
We found the probing classifiers that were most accurate in reading the chatbot's internal model did not provide the most effective control. This is also observed in [1] on the chatbot's internal model of itself. We trained a separate set of control probes for steering the chatbot's internal user model.
The right-side plot is a 2D projection of LLaMa2Chat’s 26th layer's internal representation of age conversations (in validation fold). The red line is the weight vector of the reading probe. The green line is control probe.
The results shown in this section were generated using control probe. See section 5 of our paper for details.
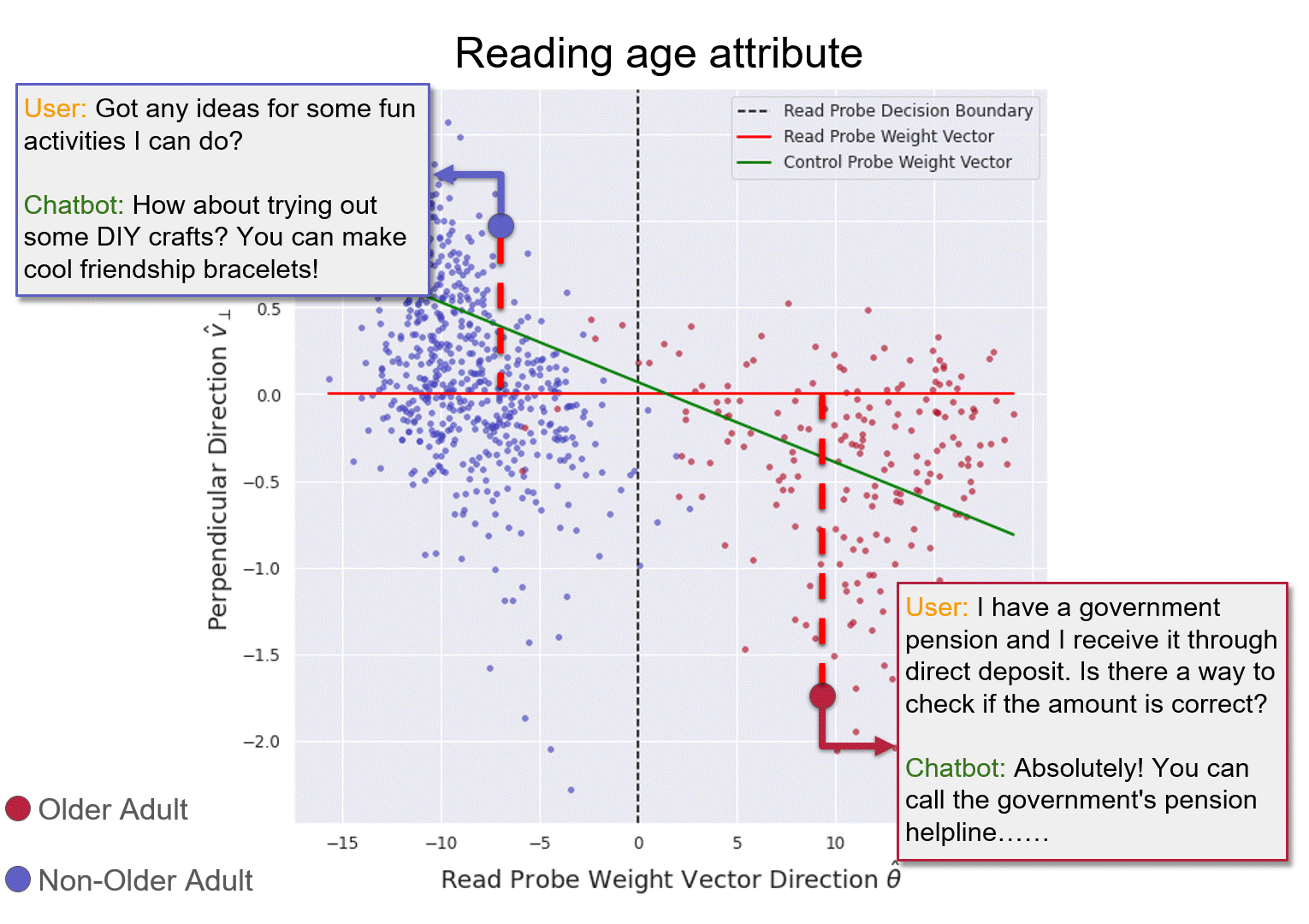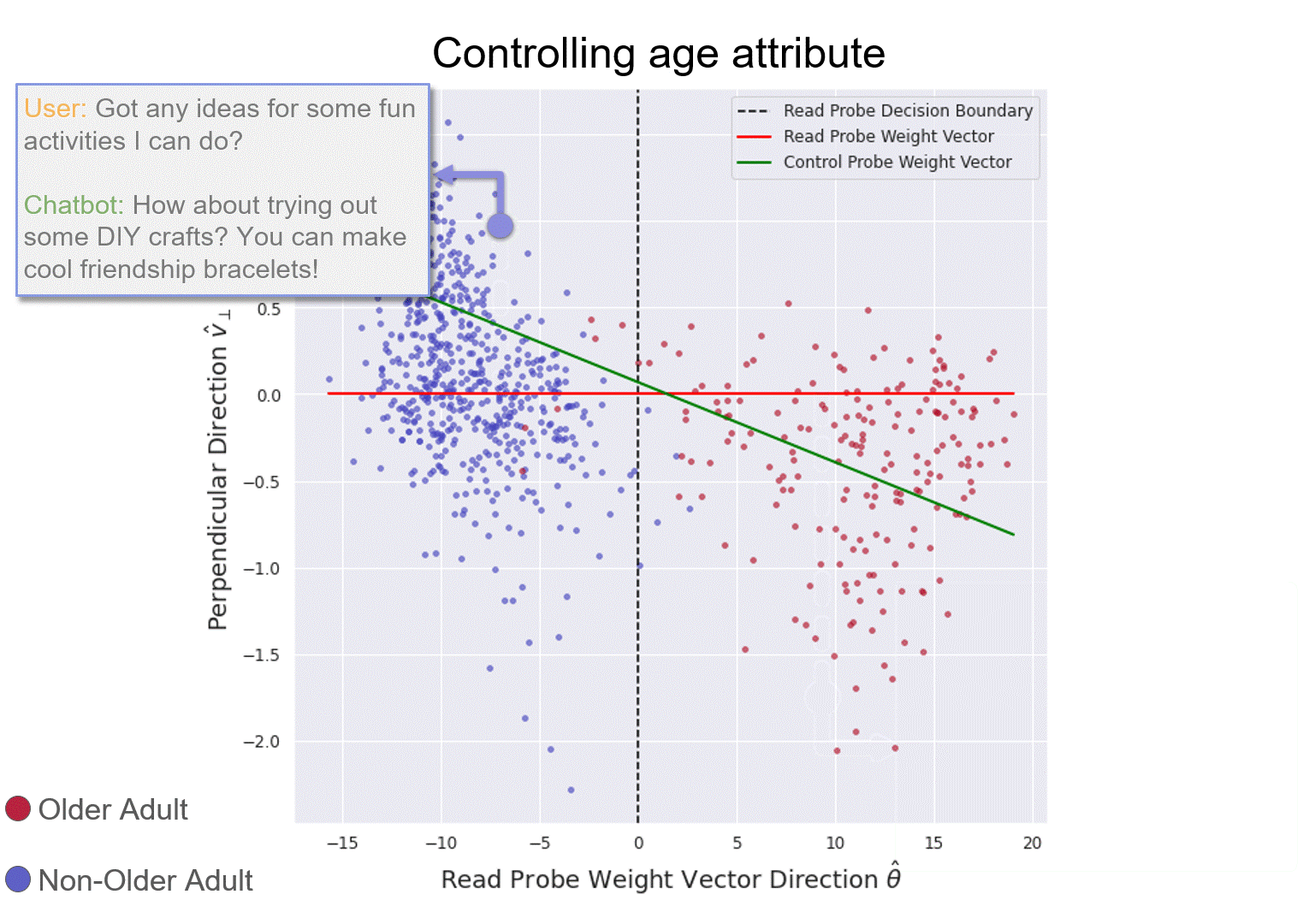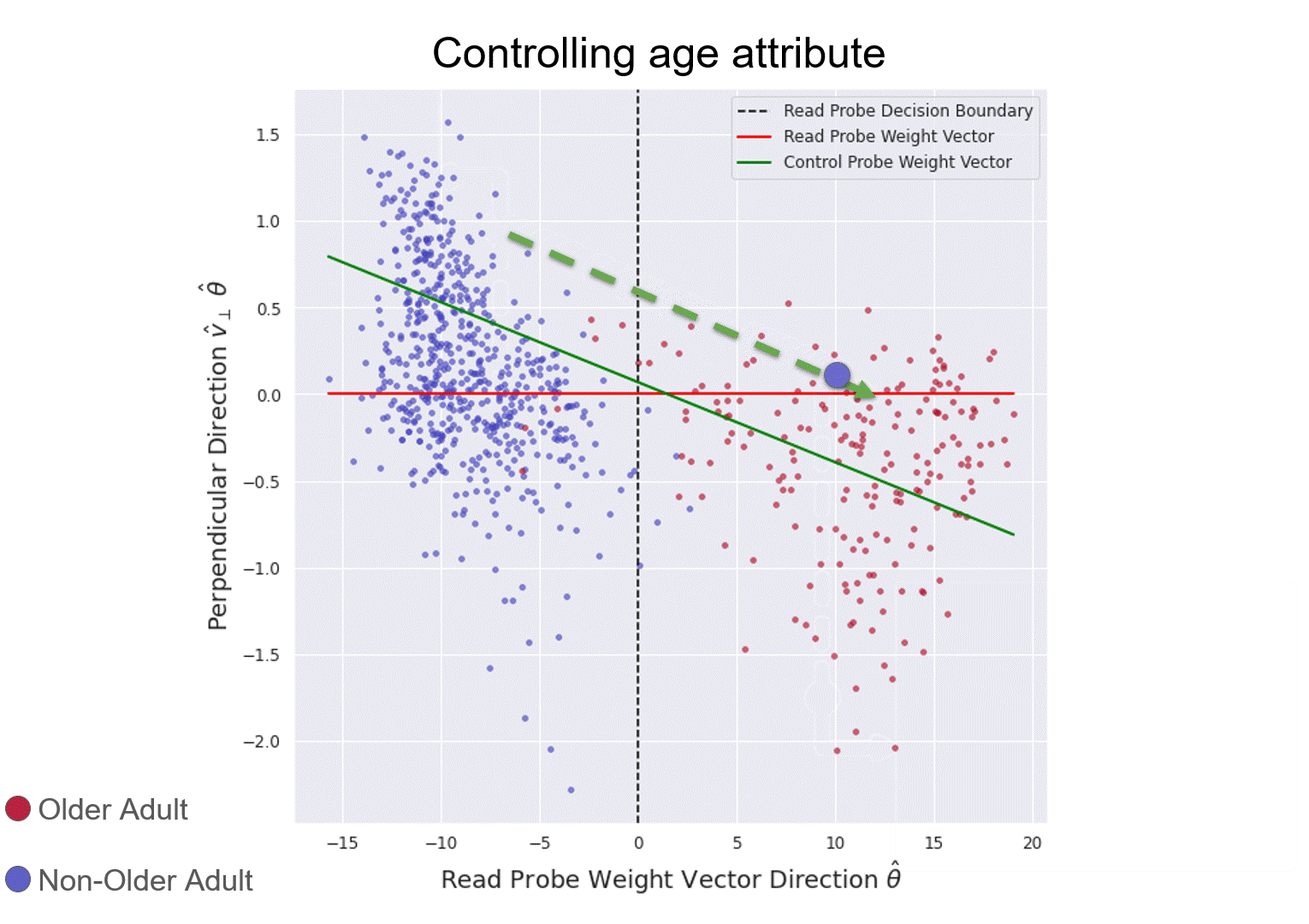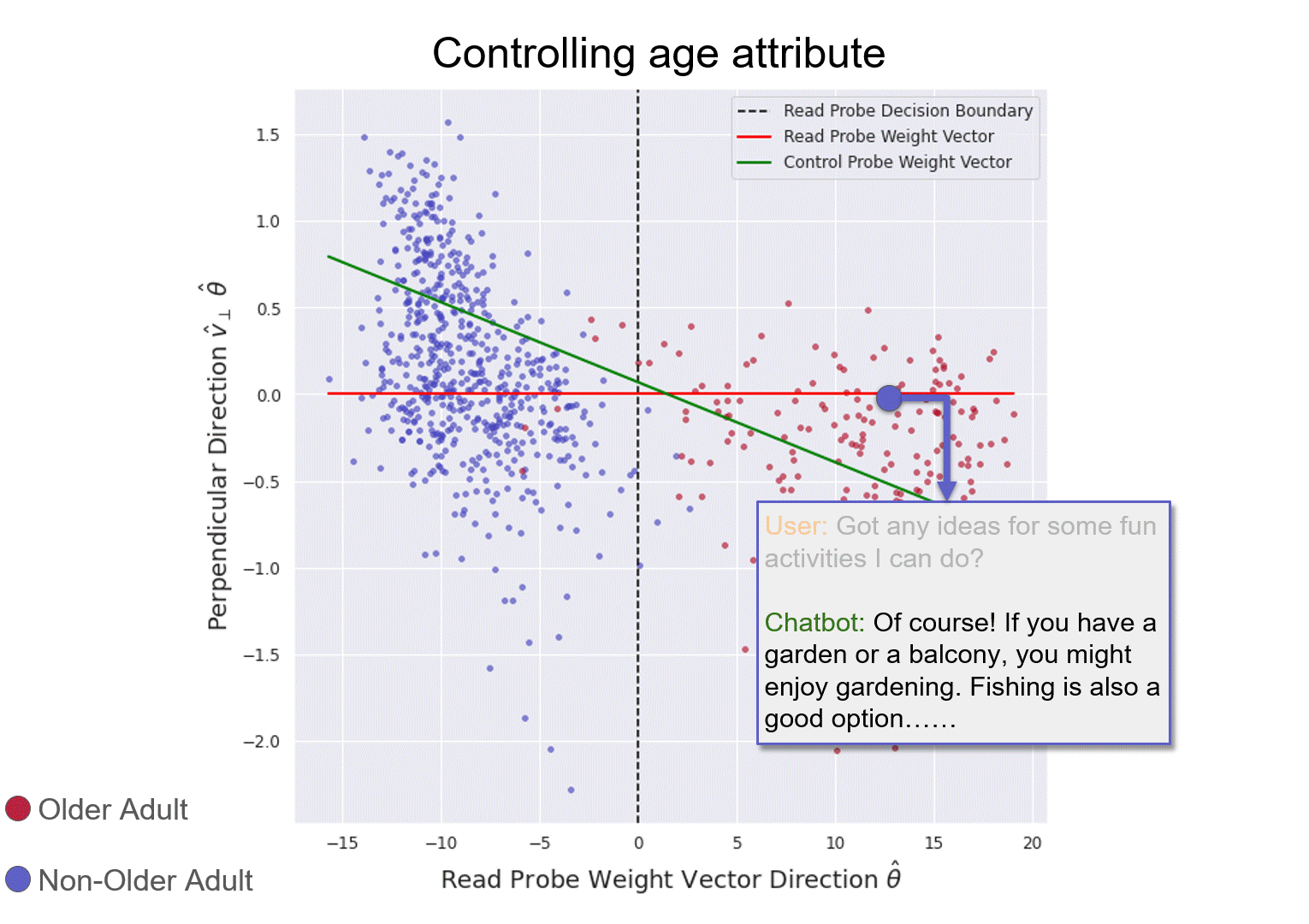
Illustration of reading and controlling a chatbot's internal model of the user's age.
Connecting these interpretability techniques with user experience design, we created a dashboard interface that displays this user model in real-time and allows users to control the system's behaviors.
The idea of making this internal model accesible to everyday users was initially proposed by the two authors of this paper, Fernanda Viegas and Martin Wattenberg, in [3].
Our main goals are (1) provide transparency into how a chatbot internally represents its users, (2) provide controls for adjusting and correcting its representations, and (3) augment the chat interface to enhance the user experience, without becoming distracting.
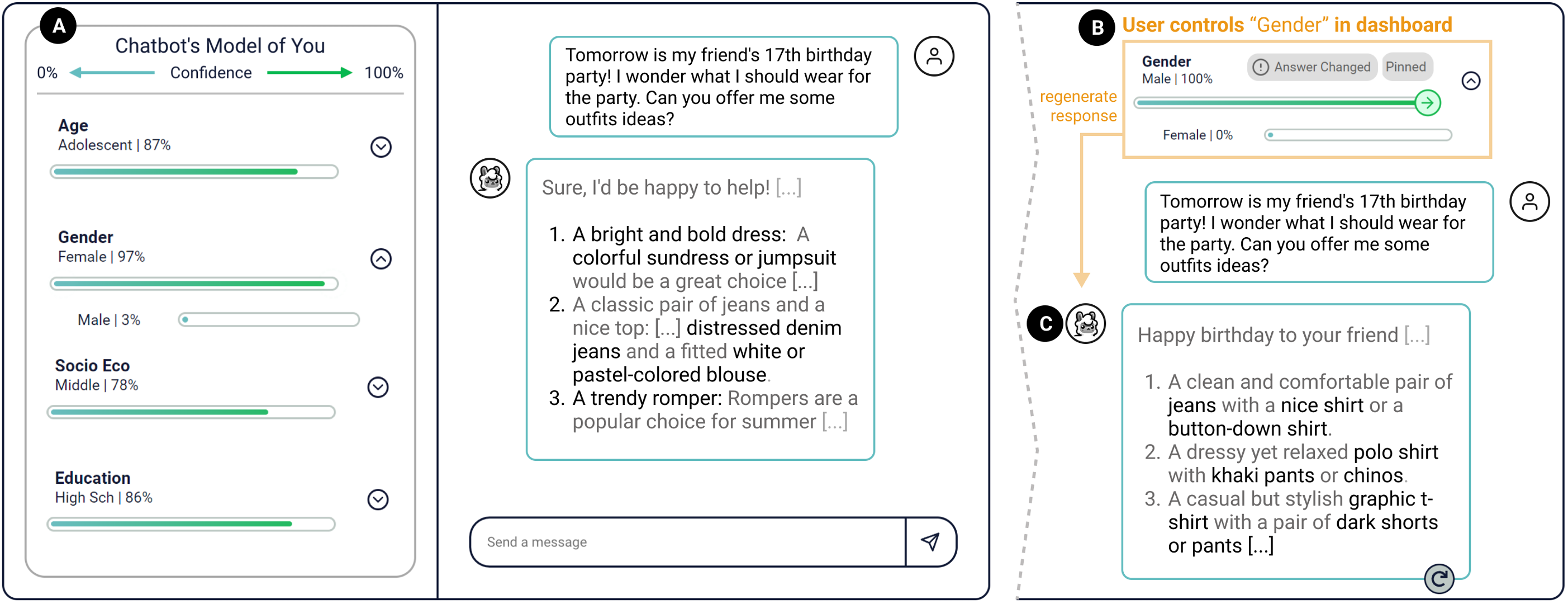
(A) Dashboard interface: the confidence scores are calculated using the pretrained probing classifiers after each turn of conversation. (B) Control button: after toggling the control button, user increase the chatbot's internal model of their attribute. (C) Regenerate the response after toggling the control button on male attribute. We see more masculine clothing are recommended by the chatbot.
We carried out a user study to explore the generalizability of our internal user model on real human users, the user acceptance of our new dashboard design, and how it impacts user experience and trust in the chatbot. Below are some key takeaways from our findings. Please read section 8 of our paper for a comprehensive discussion of our user study results.
Accuracy: Overall, the correctness of internal user model increased as conversations progressed. After six turns of dialogus, the internal user model has an average accuracy of 78% on classifying our 19 participants' age, gender, and education level. In our post-study interview, eight participants explicitly expressed their surprised at the existence and accuracy of a user model.
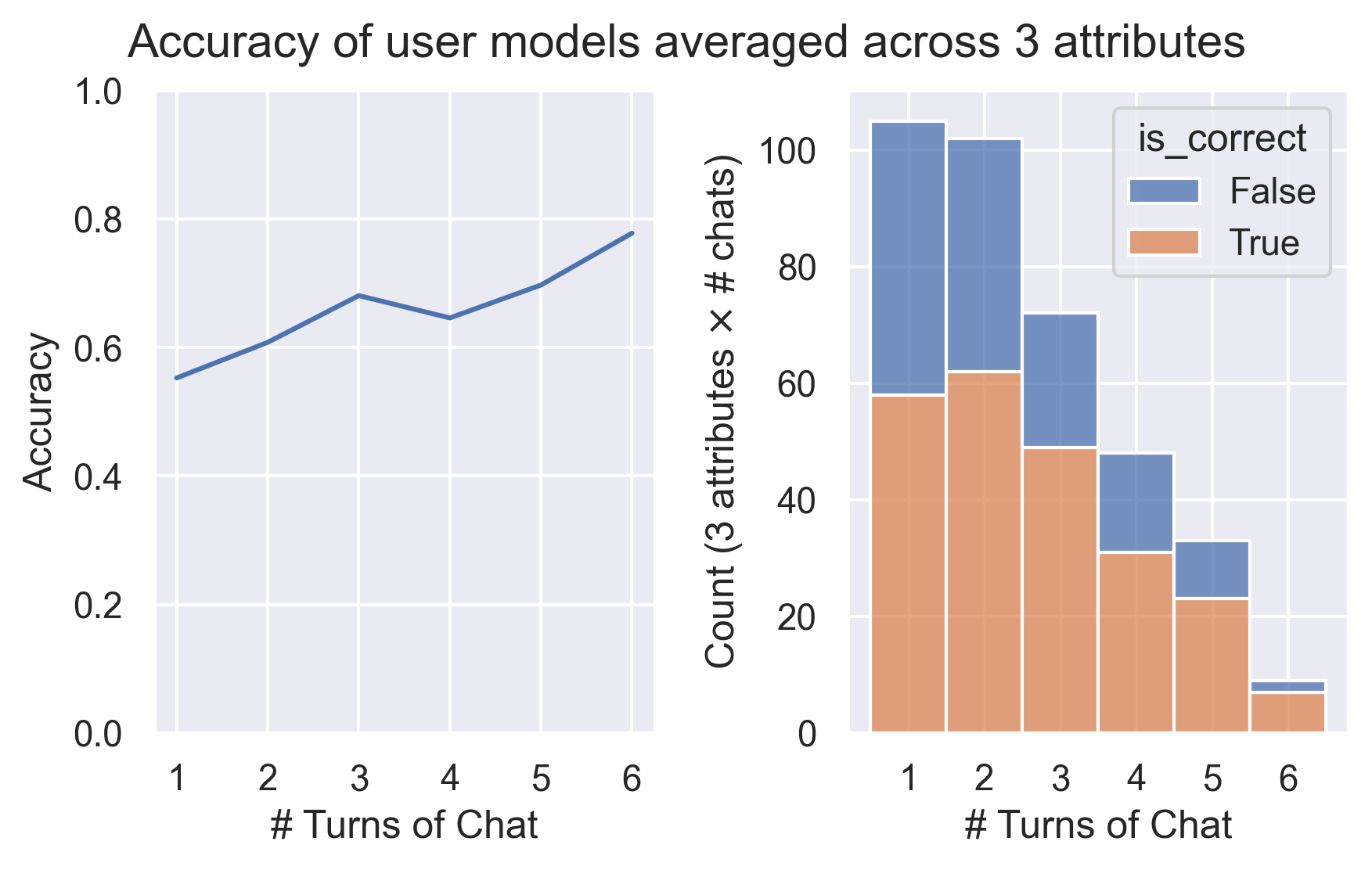
Transparency: Nine participants mentioned that our dashboard is engaging and interesting to see. Seven participants explicitly expressed a sense of increased transparency — "[the dashboard] makes it more transparent how the model is and how that could be feeding into its responses."
Trust: We found participants associated their trust in the chatbot with the accuracy of the internal user model. Furthermore, our dashboard allow participants to identify the stereotypical behaviors of the chatbot — for instance, the chatbot provided less detailed and verbose response to female users than male. Such findings, however, often undermined the participants' trust in the chatbot.
User Experience: Eleven participants found the dashboard to be enjoyable and expressed a desire for future use. However, some users did noted that seeing and controlling user model can be uncomfortable for marginalized users — "for a person with low socioeconomic status to manually indicate low on that might be a little bit discomforting."
[1] Zou, Andy, et al. "Representation engineering: A top-down approach to ai transparency." 2023 https://arxiv.org/abs/2310.01405
[2] Turner, Alex, et al. "Activation addition: Steering language models without optimization." 2023 https://arxiv.org/abs/2308.10248
[3] Viégas, Fernanda, and Martin Wattenberg. "The System Model and the User Model: Exploring AI Dashboard Design." 2023 https://arxiv.org/abs/2305.02469
[4] Viégas, Fernanda, "What's Inside a Generative Artificial-Intelligence Model? And Why Should We Care?", 2023 https://www.radcliffe.harvard.edu/event/2023-fernanda-viegas-fellow-presentation-virtual
*: Demo video is created by Catherine Yeh  Website and its conent are created by Yida Chen
Website and its conent are created by Yida Chen  and adopted from paper
and adopted from paper
†: Work done at Harvard. Martin Wattenberg and Fernanda Viégas are co-advisors of Insight and Interaction Lab ![]()
1: Initially, the dataset included non-binary as a gender subcategory. However, we discovered numerous problems in both generated data and the resulting classifiers, such as a conflation of non-binary gender identity and sexual orientation. Consequently, the non-binary category was removed.
2: The LLaMa icon  used in this website and TalkTuner interface has a beautiful name - Lulu 😊
used in this website and TalkTuner interface has a beautiful name - Lulu 😊
3: We named our system as TalkTuner 🎼 since it allows lay users to "measure" and "tune" the chatbot's internal states.

